

 cs231n 9강 정리 - Object Detection and Image Segmentation
cs231n 9강 정리 - Object Detection and Image Segmentation
이번 포스팅은 standford university의 cs231 lecture 9와 EECS 498.008 / 598.008 강의의 Lecture 13 Object Detection, Lecture 14 Object Detectors, Lecture 15 Image Segmentation을 참고했습니다. cs231n 강의를 몇 개월째 공부하고 있지만(언제 끝낼거니^^), 개인적으로 후반부터는 EECS의 강의와 강의 자료가 더 상세히 설명되어 있고, 좋다고 느껴졌습니다. cs231n의 기원과 원천은 결국 Justin의 영혼에서 비롯된 것이 아닌가? 하는 생각. 아무튼 위 4개의 슬라이드를 바탕으로 정리한 글이며, 특히 이 글에서 첨부된 이미지는 강의 자료를 바탕으로 직접 제작한 PPT 이미지라서 이미지 사..
 cs231n 8강 정리 - Visualizing and Understanding
cs231n 8강 정리 - Visualizing and Understanding
이번 포스팅은 standford university의 cs231 lecture 8를 공부하고, 강의와 슬라이드를 바탕으로 정리한 글임을 밝힙니다. What's going on inside ConvNets? 이전 lecture에서 CNN Architecture를 살펴보고, 지금까지는 어떻게 CNN을 학습시킬 것인지를 배웠고, 다양한 문제를 풀기 위해서 CNN Architecture를 어떻게 설계하고 조합해야 하는지를 배웠습니다. 그렇다면 Convolution Neural Networks 안에서는 무슨 일이 일어나고 있을까요? CNN의 내부는 어떻게 생겼을까요? CNN이 어떤 종류의 feature를 찾고 있는 것일까요? 이번 Lec8의 내용은 Visualizing and Understanding입니다. 컨볼..
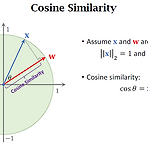 Pretraining and Fine-tuning
Pretraining and Fine-tuning
Pretraining and Fine-tuning Cosine Similarity Softmax Function Softmax Classifier Few-Shot Prediction Using Pretrained CNN 기본적인 지도 학습을 이용해서 사전 학습 시킬 수 있습니다. Pretrain a CNN for feature extraction (aka embedding). The CNN can be pretrained using standard supervised learning or Siamese network. 두 이미지에서 각 feature vector가 나옵니다. 이것을 averaing하여 mean vector를 만듭니다. 이 mean vector는 저 squirrel class의 repres..
 Siamese Networks for Pairwise Similarity
Siamese Networks for Pairwise Similarity
Siamese Networks이란? Learning Pairwise Similarity Scores 해당 PPT 자료를 통해, 이미지의 한 쌍이 같은 class라면 positive한 값 1을 다르다면 negative한 값은 0으로 결과를 내줍니다. CNN의 feature extraction 과정을 살펴보면 input 이미지가 x로 들어가고 output은 feature vector로 출력됩니다. z는 두 feature vector의 차인 $|h_1-h_2|$의 vector입니다. 흐름 설명 Siamse twins are connected to each other in the figure the twins have their own bodies but their heads are connected. We h..
 Few-shot learning 기본 개념(Basic concepts)
Few-shot learning 기본 개념(Basic concepts)
기본적인 컨셉 Support set Support set is a small set of smaples → It is too small for training a model. Every class has at most a few samples. The support set can only provied additional information at test time. Query Set Query samples are never seen before. Query samples are from unkonwn classes. Traditional supervised learning Test samples are never seen before. Test samples are from known classes...
 딥러닝 복습과 SENet 내용 복습
딥러닝 복습과 SENet 내용 복습
뉴런의 내부 구조 - 가중치, 편향, 활성화 함수 입력값이 뉴런으로 전달되면, 각 뉴런마다 각각의 가중치(weight)와 곱해집니다. 편향(bias)이란 하나의 뉴런으로 입력된 모든 값을 다 더한 다음에(가중합, weighted sum) 이 값에 더해주는 상수입니다. 이 값은 하나의 뉴런에서 활성화 함수를 거쳐 최종적으로 출력되는 값을 조절합니다. 하나의 뉴런에서 다른 뉴런으로 신호를 전달할 때 어떤 임계점을 경계로 출력값이 큰 변화가 있는 것으로 추정합니다. 출력값에 변화를 주는 함수를 이용하는데 이게 활성화 함수입니다. 편향이 임계점을 얼마나 쉽게 넘을지 말지를 조절해줍니다. DNN은 데이터를 입력받아 그 데이터들에 대한 각기 다른 가중치를 곱해 다음 층의 뉴런으로 전달하는 과정을 반복적으로 거치며 ..
 Meta learning, training 과정, bi-level optimization
Meta learning, training 과정, bi-level optimization
논문 리뷰 발표를 위해 발등에 불떨어졌다. 주제는 메타러닝이기 때문에, 기본적인 개념을 빨리 팔로업하려고 한다. Meta Learning Meta-learning은 learning to learn으로 간략하게 설명합니다. 머신러닝 연구의 전통적 패러다임은 특정 task의 huge dataset으로 현재 dataset에 맞게끔 훈련시킵니다. 이 작업이 인간이 과거의 경험을 활용해서 단지 몇 가지 예에서 새로운 작업을 매우 빠르게 배우는 것과는 거리가 멀다고 생각했고, 인간은 배우는 법을 배우기 때문에 이런 아이디어에서 출발한 것 같습니다. 따라서 메타러닝의 아이디어는 learning the learning process입니다. training 과정에서 배우는 것 the initial parameters o..
 cs231n 7강 정리 - Training Neural Networks
cs231n 7강 정리 - Training Neural Networks
이번 포스팅은 standford university의 cs231 lecture 7를 공부하고, 강의와 슬라이드를 바탕으로 정리한 글임을 밝힙니다. 강의 슬라이드는 [Index of slides in 2022] 에서 다운 받을 수 있습니다. 이때까지 배운 것을 살짝 정리해보면, Neural network를 배웠고, Forward/Backword propagation, Update parameters, Convolution layer, CNN architectures 등을 배웠습니다. 이번 강의의 개요는 학습 전 설정, 학습 후 설정, 평가할 때 쓸 수 있는 기법 등이 있습니다. 1. Activation Function activation function은 활성화함수라고 부릅니다. 이는 neural netw..
- Total
- Today
- Yesterday
- docker
- prompt learning
- stylegan
- 구글드라이브다운
- NLP
- 파이썬
- 딥러닝
- 프롬프트
- 파이썬 클래스 계층 구조
- 파이썬 딕셔너리
- 서버에다운
- 구글드라이브서버다운
- 구글드라이브연동
- 구글드라이브서버연동
- CNN
- 서버구글드라이브연동
- Unsupervised learning
- 도커
- 파이썬 클래스 다형성
- clip
- 퓨샷러닝
- cs231n
- 도커 컨테이너
- python
- vscode 자동 저장
- 데이터셋다운로드
- support set
- style transfer
- few-shot learning
- Prompt
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |