728x90
Pretraining and Fine-tuning
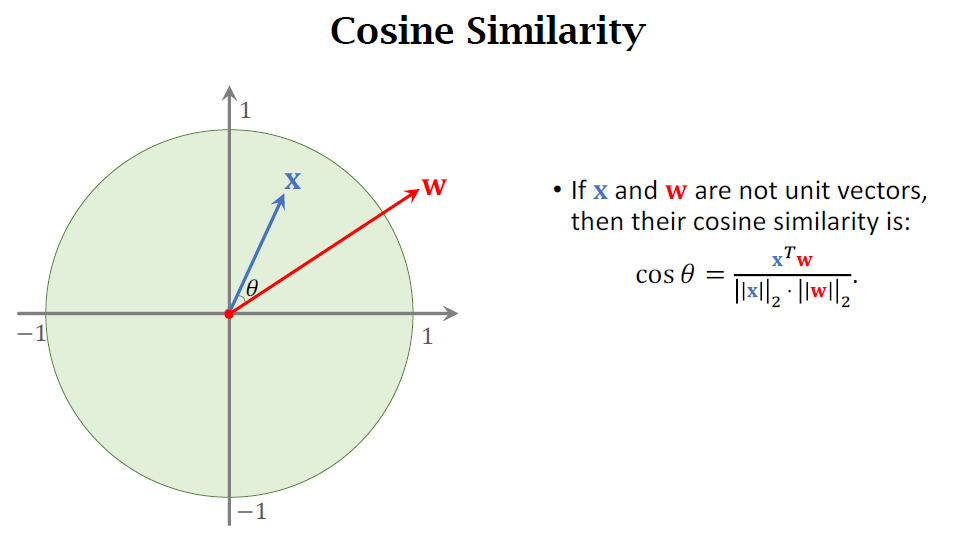
Cosine Similarity

Softmax Function


Softmax Classifier

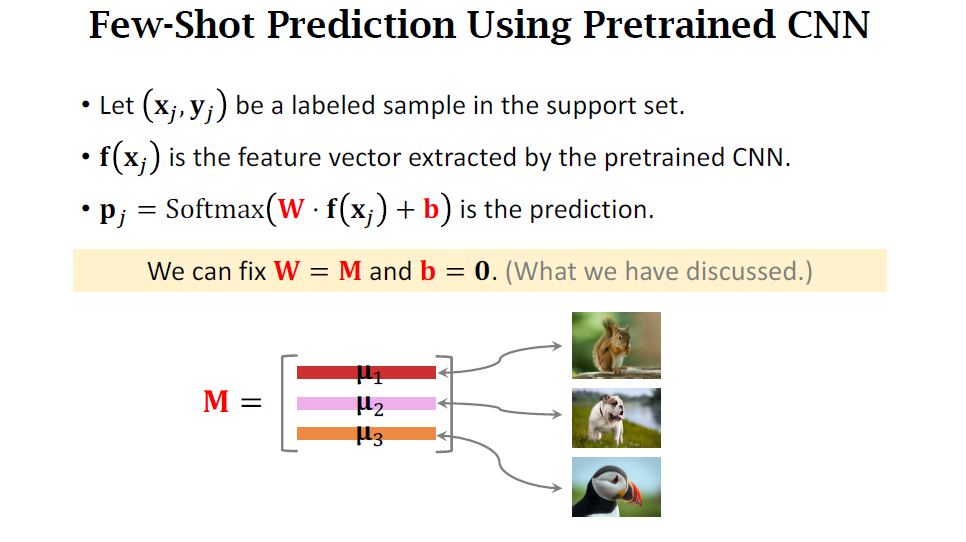
Few-Shot Prediction Using Pretrained CNN
기본적인 지도 학습을 이용해서 사전 학습 시킬 수 있습니다.
- Pretrain a CNN for feature extraction (aka embedding).
- The CNN can be pretrained using standard supervised learning or Siamese network.

- 두 이미지에서 각 feature vector가 나옵니다. 이것을 averaing하여 mean vector를 만듭니다. 이 mean vector는 저 squirrel class의 representation이 되는 겁니다.
- support set은 3 classes를 가졌기에 3개의 mean vectors를 가집니다. 즉, 3개의 representations를 가집ㅂ니다. 그 다음에 normalize합니다. 그러면 unit length를 갖게 됩니다.
- unit vector는 $\mu_1, mu_2, mu_3$로 나오며 이는 euclidean space의 class embedding입니다.
- 그리고 해당 임베딩을 통해 feature prediction을 수행할 수 있습니다.
Making Few-Shot Prediction


- matrix $M$과 feature vector $q$를 곱해서 softmax function에 넣고, output vector p를 얻습니다.
- p는 3 class에 대한 probability distribution입니다.
- 어떤 p가 가장 높을까에 대한 질문은? 당연히, 첫번째 $\mu_1^T q$가 가장 큽니다.
- q와 $\m_1$이 가장 가까우며, 첫 번째 support set이 query와 관련있는 squirrel이었기 때문입니다.
Fine-Tuning

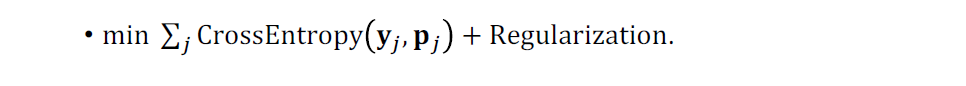
Benefit of Fine Tuning
- Fine-tuning substantially improves the prediction accuracy.
- 2% ~ 7% improvement for 5-way 1-shot.
- 1.5% ~ 4% improvement for 5-way 5-shot.
- Comparable to the sophisticated state-of-the-art methods.
Trick 1: A Good Initialization

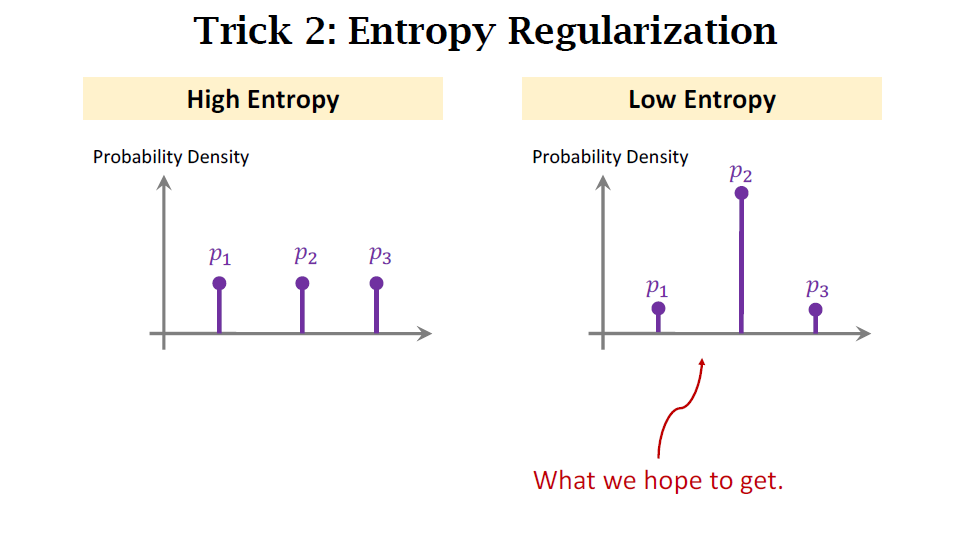
Trick 2: Entropy Regularization

Trick 3: Cosine Similarity + Softmax Classifier
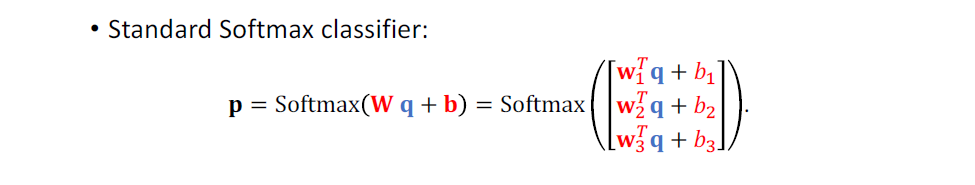


정리


자료 출처: https://youtu.be/U6uFOIURcD0
728x90
'AI > Deep Learning' 카테고리의 다른 글
| Zero-shot, Few-shot and Unsupervised Learning (0) | 2023.03.18 |
|---|---|
| 밑시딥3 정리 (0) | 2023.03.08 |
| Siamese Networks for Pairwise Similarity (0) | 2022.11.25 |
| Few-shot learning 기본 개념(Basic concepts) (0) | 2022.11.25 |
| 딥러닝 복습과 SENet 내용 복습 (0) | 2022.11.20 |



댓글