

티스토리 뷰
728x90
Siamese Networks이란?
Learning Pairwise Similarity Scores

해당 PPT 자료를 통해, 이미지의 한 쌍이 같은 class라면 positive한 값 1을 다르다면 negative한 값은 0으로 결과를 내줍니다.
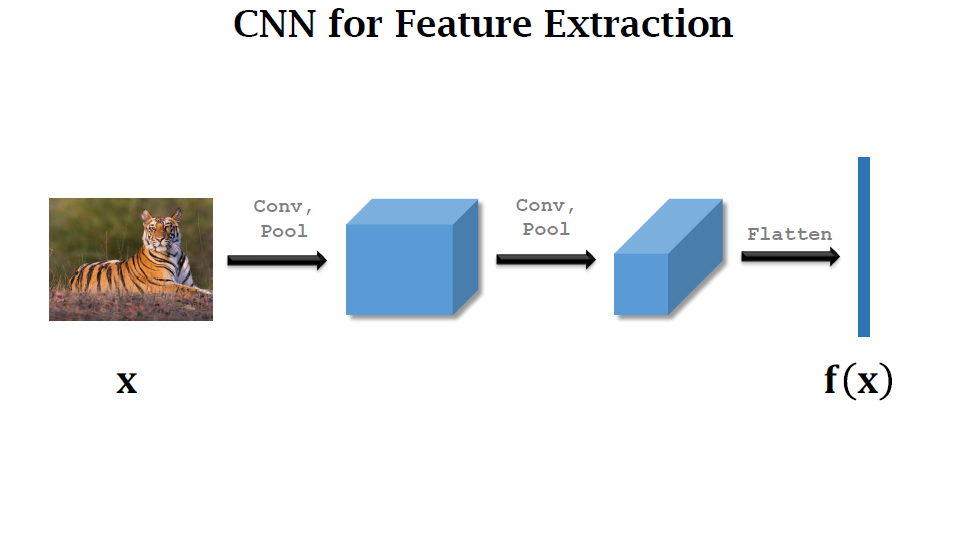
CNN의 feature extraction 과정을 살펴보면 input 이미지가 x로 들어가고 output은 feature vector로 출력됩니다.
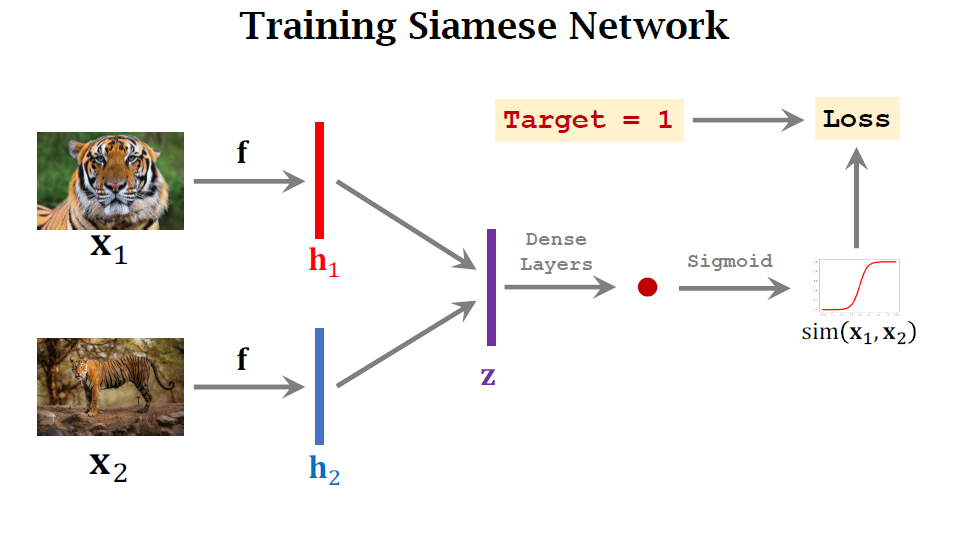
z는 두 feature vector의 차인 $|h_1-h_2|$의 vector입니다.
흐름 설명
- Siamse twins are connected to each other in the figure the twins have their own bodies but their heads are connected.
- We have previously prepared the label
- We hope the scalar output by the network is close to the target 1
- We use the loss function to measure the difference between the target the predicted scalar
- The loss can be the cross entropy of the target and the prediction. It matters the difference between the two
- Having the loss, we can use back propagation for calculating the gradients
- Then, we perform gradient descent to update the model parameters
- We can use the gradients to update the parameters of the convolutional layers
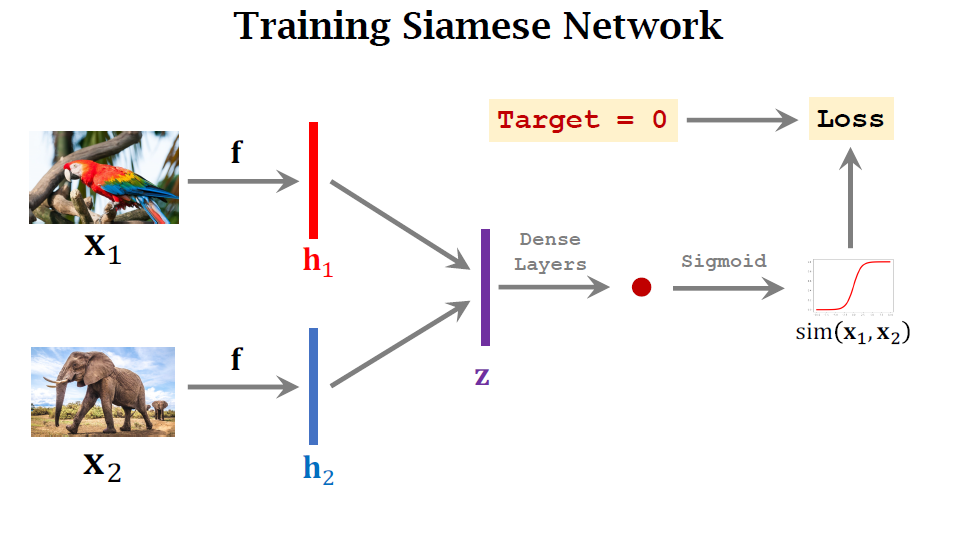
아래의 경우는 negative sample이며 0의 target을 가져야 합니다.
Triplet Loss

- Anchor이 되는 이미지를 하나 고릅니다
- 해당 class의 다른 positive 이미지를 하나 고릅니다.
- 다른 negative가 되는 이미지를 하나 고릅니다.
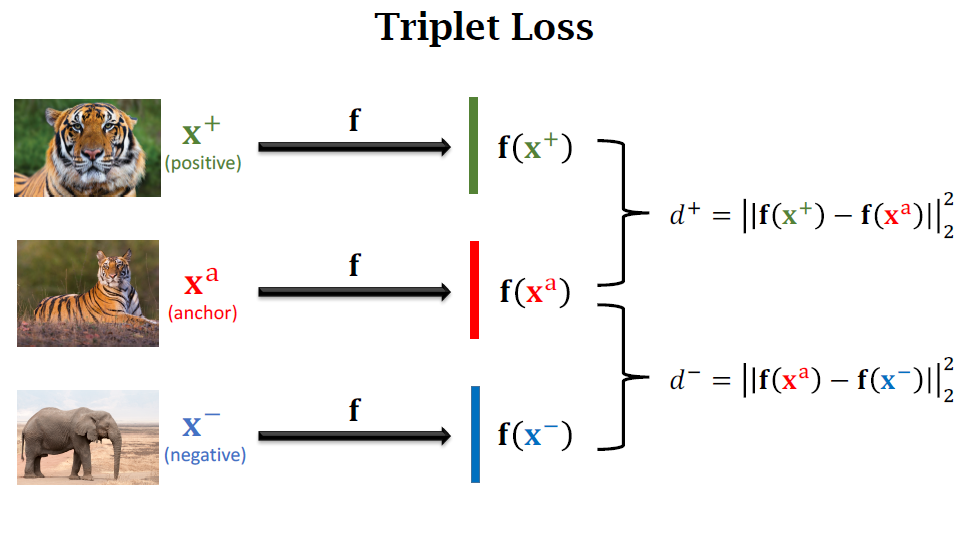
Conv layer는 3개의 이미지로부터 3개의 feature vector를 만들고, positive끼리의 $d^+$를 만들고, positive와 negative 사이의 loss $d^-$를 만듭니다.
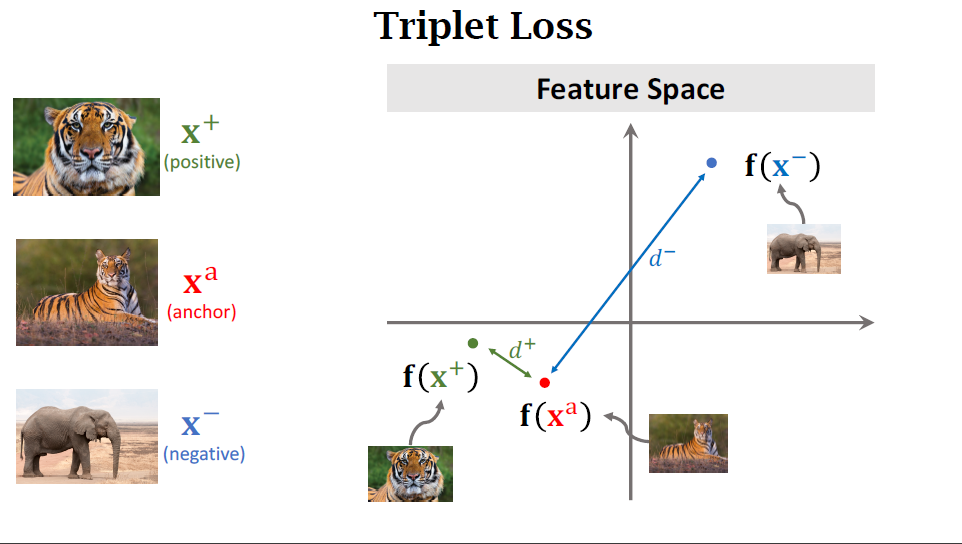
feature space에 feature vector를 위치시켜 봅니다. 위에서 계산한 $d^+$와 $d^-$를 시각적으로 이해할 수 있습니다.

- $d^+$은 작아야 합니다.
- $d^-$은 커야 합니다.
- 만약 $d^-$가 $d^+ +\alpha$보다 크다면, 그땐 loss가 없습니다. $\alpha$는 positive한 값이며 margin입니다. $d^-$ loss가 더 크길 바라는 것입니다.
- 따라서 loss는 $d^+ + \alpha - d^-$이고, $max(0, d^+ + \alpha - d^-)$입니다.
- 해당 loss를 바탕으로 CNN은 줄여나가며 파라미터를 업데이트합니다.
정리
- Train a Siamese network on large-scale training set.
- Given a support set of 𝑘-way 𝑛-shot.
- 𝑘-way means 𝑘 classes.
- 𝑛-shot means every class has 𝑛 samples.
- The training set does not contain the 𝑘 classes.
- Given a query, predict its class.
- Use the Siamese network to compute similarity or distance.
자료 출처:
728x90
'AI > Deep Learning' 카테고리의 다른 글
| 밑시딥3 정리 (0) | 2023.03.08 |
|---|---|
| Pretraining and Fine-tuning (0) | 2022.11.25 |
| Few-shot learning 기본 개념(Basic concepts) (0) | 2022.11.25 |
| 딥러닝 복습과 SENet 내용 복습 (0) | 2022.11.20 |
| Meta learning, training 과정, bi-level optimization (0) | 2022.11.16 |
댓글
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- 파이썬 딕셔너리
- docker
- 파이썬 클래스 다형성
- stylegan
- 리눅스 nano
- 파이썬 클래스 계층 구조
- 서버구글드라이브연동
- Prompt
- few-shot learning
- 파이썬
- python
- 도커
- 리눅스 나노
- 퓨샷러닝
- Unsupervised learning
- NLP
- 리눅스 나노 사용
- clip
- CNN
- 딥러닝
- prompt learning
- linux nano
- style transfer
- 프롬프트
- cs231n
- 리눅스
- 도커 컨테이너
- 도커 작업
- 구글드라이브연동
- support set
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
글 보관함
250x250