

티스토리 뷰
<순서>
- Array(배열)
- List(리스트)
- LinkedList(링크드 리스트)
- Stack(스택)
- Queue(큐)
- Dequeue(디큐)
- Tree(트리)
- Heap(힙)
- Graph(그래프)
0. 자료구조와 알고리즘이란?
- 자료구조는 데이터를 원하는 규칙 또는 목적에 맞게 저장하기 위한 구조입니다. 알고리즘은 자료구조에 쌓인 데이터를 활용하여 어떤 문제를 해결하기 위한 여러 동작의 모임입니다.
1. Array
가장 기본적 자료 구조로, 논리적 저장 순서와 물리적 저장 순서가 일치합니다. 따라서 index로 해당 원소(element)에 접근이 가능합니다. 찾고자 하는 원소의 인덱스 값을 안다면 Big-O(1)에 해당 원소로 접근 가능합니다.
- 즉, random access 가 가능합니다. 이 말의 뜻은 어떤 위치라도 접근 가능함을 의미합니다.
- 삽입과 삭제의 경우, 해당 원소에 접근하여 작업을 완료한 뒤 인덱스를 shift 해줘야 하므로 O(n)의 시간을 요구합니다.
2. List
array(배열)의 크기는 고정이기 때문에, 자료형의 크기가 가변하는 상황이라면 list를 사용합니다.
3. Linked List
그래서 나온 것이 Linked list이며, 이는 한 개의 node가 다른 node에 대한 참조만 갖고 있는 구조입니다. 따라서 array에 비해 공간적 제약을 받지 않습니다.
또한, 뒤의 요소를 전부 앞으로 이동시켜야 하는 array와 달리 Linked list는 앞뒤 요소의 값만 바꾸어주면 됩니다.
Linked list는 논리적 저장 위치와 물리적 위치가 다르므로, 원하는 위치에 삽입하려면 첫 번째 원소부터 다 확인해봐야 합니다.
이 과정으로 어떤 원소를 삭제하거나 추가하고자 했을 떄, 그 원소를 찾기 위한 O(n)의 시간이 추가적으로 발생하고 정렬이 뒤따릅니다.
- Sequencial Access를 지원한다. 어떤 요소를 접근할 때 순차적으로 검색하며 찾아야 한다는 것을 의미합니다.
- 따라서 특정 요소에 접근할 때 시간 복잡도는 O(n)입니다.
+) 정리
- ArrayList는 빈 공간이 있는 경우, 새로운 요소를 추가할 때 O(n)이지만, 여유 공간이 없는 경우엔 O(n)입니다.
- LinkedList는 search에도 O(n), 삽입/삭제에 대해서도 O(n)의 시간 복잡도를 갖습니다. Tree의 근간이 되는 자료구조입니다.
+) <list와 set의 차이점>
- List는 중복이 허용되지만 Set은 중복이 허용되지 않습니다.
- List의 중복 데이터를 Set에 넣으면 제거됩니다.
- DB를 distinct 연산하는 효과가 있습니다.
4. Stack(스택)
데이터를 저장하는 자료형입니다.
선형 자료구조의 일종으로 First In Last Out(FILO) or Last In First Out(LIFO)입니다.
- 먼저 들어간 원소가 나중에 나옵니다. = 나중에 들어간 원소가 먼저 나옵니다.
5. Queue(큐)
데이터를 저장하는 자료형입니다.
선형 자료구조의 일종으로 First In First Out(FIFO)입니다.
먼저 들어간 원소가 먼저 나옵니다.
차곡차곡 쌓이는 Stack과 다른 구조라고 볼 수 있습니다.
+) Priority Queue(우선순위 큐)와 Heap(힙)
우선순위 큐는 들어간 순서에 상관없이 우선순위가 높은 데이터가 먼저 나오는 것을 의미합니다. 이는 Heap(힙)이라는 자료구조를 갖고 구현할 수 있습니다.
이를 array나 LinkedList로 구현할 시, 우선 순위의 위치를 찾아서 삽입해야 하므로 탐색하는 시간 복잡도가 추가로 발생합니다. 따라서 Heap으로 구현을 합니다. 이 경우, 삭제나 삽입에서 노드에 저장된 값을 우선순위로 보고 모두 부모와 자식 간의 비교만 계속해서 이루어지기 때문입니다. (힙은 루트 노드에 우선순위가 높은 데이터를 위치시키는 자료구조이기 때문에)
아래 8번 Heap(힙)에서 더 다루도록 하겠습니다.
6. Dequeue(디큐, 덱)
double-ended queue로 양쪽 끝에서 삽입과 삭제가 모두 가능한 자료 구조의 한 형태입니다.
두 개의 포인터를 사용하여, 양쪽에서 삭제와 삽입을 발생할 수 있으며 큐와 스택을 합친 형태로 생각할 수 있습니다.
보통 입력과 출력을 추가하는 방식으로 사용하는데, 스택이나 큐에서 양쪽에서 입력하거나 출력하고 싶은 경우에 사용합니다.
따라서 스케줄링이 복잡해질수록 덱을 사용하는 경우가 더 많으며, 우선순위를 조절해야 할 경우가 있을 때 앞뒤로 인출이 가능한 덱(Deque)을 사용하게 됩니다.
7. Tree(트리)
트리는 스택이나 큐와 달리 비선형 자료구조입니다.
트리는 계층적 관계(Hierachical Relationship)을 표현하는 자료구조입니다.
트리를 구성하는 구성 요소들은 아래와 같습니다.
- Node (노드) : 트리를 구성하고 있는 각각의 요소를 의미한다.
- Edge (간선) : 트리를 구성하기 위해 노드와 노드를 연결하는 선을 의미한다.
- Root Node (루트 노드) : 트리 구조에서 최상위에 있는 노드를 의미한다.
- Terminal Node ( = leaf Node, 단말 노드) : 하위에 다른 노드가 연결되어 있지 않은 노드를 의미한다.
- Internal Node (내부노드, 비단말 노드) : 단말 노드를 제외한 모든 노드로 루트 노드를 포함한다.
용어 참고 [1]
트리의 구조는 다양합니다.
- Binary Tree(이진 트리)
그리고 이진 트리의 분류를
- Perfect Binary Tree (포화 이진 트리)
- Complete Binary Tree (완전 이진 트리)
- Full Binary Tree (정 이진 트리)
이와 같이 할 수 있습니다.
+) Binary Tree(이진 트리)
루트 노드를 중심으로 두 개의 서브 트리로 나뉘어지는 구조입니다. 서브트리도 동일하게 두 개의 노드를 갖습니다. 트리에선 층별로 각 숫자를 매겨서 Level(레빌)이라 하는데, 0부터 시작하고 루트 노드의 레벨은 0입니다.
+) 포화 이진 트리(Full binary tree)
각 레벨에 노드가 꽉 차 있는 이진 트리를 의미합니다.
+) 완전 이진트리(complete binary tree)
높이가 k일 때 레벨 0부터 k-1까지는 노드가 모두 채워져 있고, 마지막 레벨 k에서는 왼쪽부터 오른쪽으로 순서대로 노드가 채워져 있는 구조를 뜻합니다.
마지막 레벨에서는 노드가 꽉 차 있지 않아도 되지만 중간에 빈 곳이 있어서는 안 됩니다.
포화 이진 트리는 항상 완전 이진 트리지만 그 역은 성립되지 않습니다.
8. Heap(힙)
힙은 Complete Binary Tree(완전 이진 트리)입니다.
모든 노드에 저장된 값(우선 순위)들은 자식 노드의 것보다 크거나 같습니다.
직접 연결된 부모와 자식 노드 간의 크기만 비교하면 됩니다. 힙으로 우선순위 큐를 구현할 때 노드에 저장된 값을 우선 순위로 봅니다. 따라서 힙은 루트 노드에 우선순위가 높은 데이터를 위치시키는 자료구조입니다.
- Max Heap(최대 힙)은 완전 이진 트리이면서, 루트 노드로 올라갈수록 저장된 값이 커지는 구조입니다.
- Min Heap(최소 힙)은 완전 이지 트리이면서, 루느 노드로 올라갈수록 저장된 값이 작아지는 구조입니다.
서로 반대 개념입니다.
Max Heap에서는 루트 노드의 값이 가장 크므로 최대값을 찾는데 소요되는 연산은 O(1)입니다. 그리고 완전 이진 트리이므로 배열을 사용하여 효율적 관리가 가능합니다. (→ random accress 가능)
heap의 구조를 계속 유지하기 위해선 제거된 루트 노드를 대체할 다른 노드가 필요합니다. 따라서 맨 마지막 노드를 루트 노드로 대체하고 다시 과정을 거쳐 heap 구조를 유지합니다.
따라서 결국 O(log n)의 시간 복잡도로 최대값 또는 최소값에 접근합니다.
9. Graph(그래프)
정점과 간선의 집합이라 표현하고 트리 또한 그래프입니다.
그래프 종류로 Undirected Graph, Directed Graph가 있는데, 정점과 간선의 연결관계에 있어 방향성이 없는 그래프를 Undirected Graph라 하고, 간선에 방향성이 포함되어 있는 그래프를 Directed Graph라고 합니다.
그래프에 대한 개념은 많은 것 같은데 탐색 방법인 DFS, BFS를 더 살펴보고 가겠습니다.
그래프는 정점의 구성, 간선의 연결에 규칙이 존재하지 않아 탐색이 복잡합니다. 따라서 탐색하기 위한 방법으로 두 가지 알고리즘을 기반으로 합니다.
- 깊이 우선 탐색(Depth First Search: DFS)
- 너비 우선 탐색(Breadth First Search: BFS)
- 정점(vertex), 간선(edge)
+) 깊이 우선 탐색(Depth First Search: DFS)
그래프 상에 존재하는 임의의 한 정점으로부터 연결되어 있는 한 정점으로만 나아간다라는 방법을 우선으로 탐색합니다.
일단 연결된 정점으로 탐색을 시작합니다.
연결할 수 있는 정점이 있을 때까지 계속 연결하다가 더이상 연결되지 않은 정점이 없으면 바로 그 전 단계의 정점으로 돌아가서 연결할 수 있는 정점이 있는지 살펴봅니다.
이는 미로 찾기로 설명되는데 정점을 타고 들어가다가 더 이상 다른 이웃이 없는 정점을 만나면 갔던 길을 되돌아 와서 방문을 재개합니다.
해당 경우엔 Stack의 자료 구조를 사용합니다
Time Complexity : O(V+E) … vertex 개수 + edge 개수
+) 너비 우선 탐색(Breadth First Search: BFS)
그래프 상에 존재하는 임의의 한 정점으로부터 연결되어 있는 모든 정점으로 나아갑니다. 시작 정점으로부터 가까운 정점을 먼저 방문합니다. 멀리 떨어져 있을 수록 나중에 방문합니다.
Tree 에서의 Level Order Traversal 형식으로 진행됩니다. BFS 에서는 자료구조로 Queue를 사용합니다.
연락을 취할 정점의 순서를 기록하기 위함인데요. 우선, 탐색을 시작하는 정점을 Queue 에 넣습니다(enqueue). 그리고 dequeue 를 하면서 dequeue 하는 정점과 간선으로 연결되어 있는 정점들을 enqueue합니다.
즉, vertex 들을 방문한 순서대로 queue 에 저장하는 방법을 사용하는 것입니다.
Time Complexity : O(V+E) … vertex 개수 + edge 개수
BFS 로 구한 경로는 최단 경로입니다.
+) DFS/BFS 정리
DFS
- 순환 알고리즘
- 트리 순회는 모두 DFS의 한 종류
- 모든 노드를 방문하고자 할 때 이 방법을 선택함(완전 탐색 알고리즘에 이용)
BFS
- 재귀적으로 동작하지 않습니다.
- 방문한 노드를 차례로 저장한 후 꺼낼 수 있는 큐(Queue) 자료구조 사용
- 두 노드 사이의 최단 경로 혹은 임의의 경로를 찾고 싶을 때 사용
공통점
- 그래프 탐색의 경우 어떤 노드를 방문했었는지 여부를 반드시 검사해야 합니다.
10. Hash(해시)
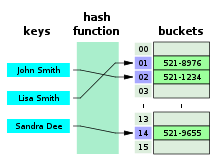
해시는 배열을 사용하여 데이터를 저장하여 빠른 검색 속도를 갖습니다. 특정값을 Search하는데 데이터 고유의 인덱스로 접근하게 되므로, O(1)이 됩니다.
하지만 이 인덱스로 저장되는 key값이 불규칙한 경우도 있습니다.
따라서 특별한 알고리즘을 이용해서 저장할 데이터와 연관된 고유한 숫자를 만들어 내서 이를 인덱스로 활용합니다.
이 인덱스는 고유한 위치이기 때문에 삽입 연산 시 다른 데이터 사이에 끼어 들거나, 삭제 시 다른 데이터로 채울 필요가 없어서 연산할 때 추가 비용이 들지 않습니다.
그 알고리즘이 Hash Table입니다. 해시 테이블을 구현하기 위해서 LinkedList와 Hash function이 필요합니다.
저장되는 값들의 key 값을 hash function을 통해 작은 범위의 값들로 바꿔주고, 동일한 key 값에 복수 데이터가 하나의 테이블에 존재하는 Collision 현상이 발생하지 않도록 저장해야 합니다.
따라서 키의 일부분을 참조해서 해시 값을 만들기 보다 키 전체를 참조해서 해시 값을 만들어 냅니다. 충돌을 막는 기본적인 두 가지 방법에 대해 알아보겠습니다.
+) Open Address 방식 (개방주소법)
해시 충돌 시, 다른 해시 버킷에 해당 자료를 삽입하는 방식입니다. 버킷은 데이터를 저장하기 위한 공간을 의미합니다.
다른 해시 버킷을 찾기 위해
1. Linear Probing: 순차적으로 탐색하여 빈 버킷 찾을 때까지 반복
2. Quadratic probing: 2차 함수를 이용해 탐색할 위치 찾기
3. Double hashing probing: 하나의 해시 함수에 충돌 발생 시, 2차 해시 함수를 이용해 새로운 주소를 할당. 많은 연산량 필요
+) Separate Chaining 방식 (분리 연결법)
Open Addressing은 해시 버킷을 채운 밀도가 높아질수록 worst case(빈 버킷을 찾지 못하고 탐색을 시작한 위치로 돌아오는 것) 발생 빈도가 높아집니다.
반면 Separate Chainging 방식의 경우, 해시 충돌이 잘 발생하지 않도록 보조 해시 함수로 조정할 수 있습니다.
두 가지 구현 방식이 존재합니다.
1. LinkedList
각 버킷들을 연결 리스트로 만들어서 충돌이 발생하면 해당 버킷의 리스트에 추가합니다. 연결 리스트의 특징을 그대로 이어 받아 삭제와 삽입이 간단하고, 작은 데이터를 저장할 때 오버헤드가 부담이 됩니다. 버킷을 계속해서 사용하는 Open Address 방식에 비해 테이블 확장을 늦출 수 있습니다.
2. Red-Black Tree
연결 리스트 대신 트리를 사용합니다. 결정 기준은 하나의 해시 버킷에 할당된 key-value paris의 개수입니다. 데이터의 개수가 적다면 연결 리스트이 더 적절합니다.
참고
'Skills > DS & Algorithms' 카테고리의 다른 글
| Peak Finding in 1 or 2D array (0) | 2022.10.24 |
|---|---|
| [Tree] AVL Tree (Balanced BST) - 균형 이진 탐색 트리 (0) | 2022.10.12 |
| [Sorting] Insertion, Merge Sort (2) | 2022.09.21 |
- Total
- Today
- Yesterday
- 리눅스 나노
- 파이썬 클래스 계층 구조
- docker
- 리눅스
- style transfer
- Prompt
- 서버구글드라이브연동
- 리눅스 nano
- clip
- 리눅스 나노 사용
- 파이썬 클래스 다형성
- 퓨샷러닝
- support set
- NLP
- Unsupervised learning
- 도커 작업
- prompt learning
- CNN
- few-shot learning
- 파이썬 딕셔너리
- python
- 도커 컨테이너
- cs231n
- 구글드라이브연동
- linux nano
- 도커
- 파이썬
- 딥러닝
- 프롬프트
- stylegan
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |