

티스토리 뷰

2017년 CVPR에서 발표된 논문 Pyramid Scene Parsing Network입니다. PSPNet이라고 불리며, 주요 키워드는 pyramid pooling module, global context information, different-region-based context aggregation 등이라 볼 수 있습니다.
기본 개념
- Semantic Segmentation은 각 픽셀값을 특정 클래스(class)로 분류하는 것
- Segmentation과 Detection 차이
- Object Detection의 경우, 이미지의 각 class마다 bounding box를 만듦, 객체의 모양을 알 수는 없음
- Image segmentation은 각 object마다 pixel-wise mask를 만들어서 object에 대한 세부 정보를 이해하는데 더 유용함
해당 논문을 이해하기 위해 알면 좋은 것
- Semantic Segmentation 기본 개념
- FCN (Fully Convolution Network)
- GoogleNet 관련 내용(본인도 공부중)
- scene parsing , sub-region , 1x1 Conv , dilated convolution 등
1. Introduction
- PSPNet은 CVPR 2017년에 발표된 Semantic Segmentation algorithm입니다.
- 해당 논문은 1) PSPNet과 2) Pyramid pooling module을 통해 다른 영역별 context를 집계하여 global context information의 기능을 활용합니다.
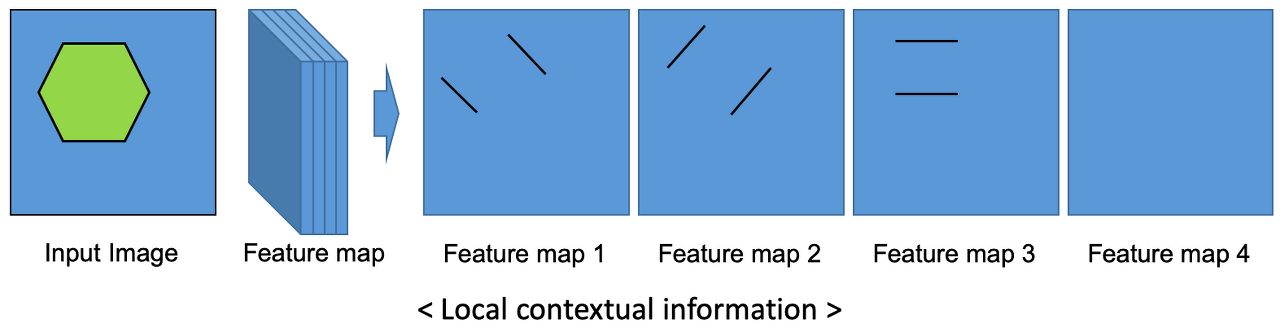
- Local context information
- Local context information에 해당하는 대표적인 정보로는 모양, 형상, 재질의 특성 등이 있습니다. 즉, 특정 영역의 고유 정보(모양, 형상, 재질등)에 해당합니다.
- 각 feature map들은 가지는 값에 따라 다양한 필터 역할을 가질 수 있습니다. feature map의 핵심이 되는 영역과 이에 대응되는 입력 이미지의 특정 영역에서 물체를 인지할 수 있습니다. 즉, 앞에서 언급한 global한 영역을 보지는 않습니다.
- Global contextual information
- 형상과 주변 상황을 모두 고려합니다. 따라서 Segmentaion에 있어서 더 좋은 성능을 얻을 수 있습니다.
- 어떤 픽셀값의 클래스를 분류하기 위해 단순히 그 근처의 local 정보들만 이용하지 않고 좀 더 넓은 영역(Global)을 고려합니다.
- Scene parsing 의 경우, 이미지 내의 모든 픽셀에 대해 카테고리화하는 것을 의미합니다. 따라서 이미지의 모든 픽셀을 대상으로 정보값이 있어야 합니다.
- global한 표현은 scene parsing 작업에서 좋은 결과를 갖고 오는데 효과적이며, pixel-level 예측을 위한 프레임워크를 제공합니다.
PSPNet은
- FCN(pixel prediction framework)과 ResNet(deeply supervised loss)를 baseline으로 둡니다.
+) 해당 논문에서 왜 하필 FCN은 왜 자꾸 들먹이는지? (그전의 UNet과 DeepLab도 있는데)
- FCN은 global scene을 활용을 못해 complex scene parsing에서 잘 동작하지 않는다.
- 가장 기본적인 Convolution / Transpose Convolution을 사용함
- But, PSPNet은 Dilated Convolution을 사용
- Dilated convolution은 특히 real-time segmentation 분야에서 주로 사용됨
- 더 넓은 시야가 필요하고, 여러 conv나 큰 kernel을 사용할 여유가 없는 경우에 사용함
- 특징: pooling을 수행하지 않고도 receptive field를 크게 가져갈 수 있기 때문에 spatial dimension 손실이 적고 대부분의 weight가 0이기 때문에 연산의 효율이 좋음
- 결과: receptive field를 넓혀줌 → 더 많은 영역을 보면서 contextual information을 획득 가능!
3. Pyramid Scene Parsing Network
Several common issues for complex-scene parsing
FCN methods를 활영하여 scene parsing을 할 경우의 실패 케이스를 관찰합니다. 이것이 ptramid pooing module을 제안하는데 동기가 되었으며 해당 network는 figure3으로 보여드리겠습니다.
기존 FCN을 기본으로 설계된 모델은 feature map에 존재하는 local contextual information(모양, 형상, 재질 등의 특성)을 활용하였습니다.
문제점: 그래서 비슷한 형상 또는 재질을 가진 object를 잘 구별하지 못하였음
따라서 PSPNet은 local and global contextual information을 Semantic Segmentation을 하기 위한 또 하나의 기준(metric)으로 활용합니다.
PSPNet의 논문에서 제시하고 있는 complex-scene parsing에 대한 이슈를 더 살펴보겠습니다.
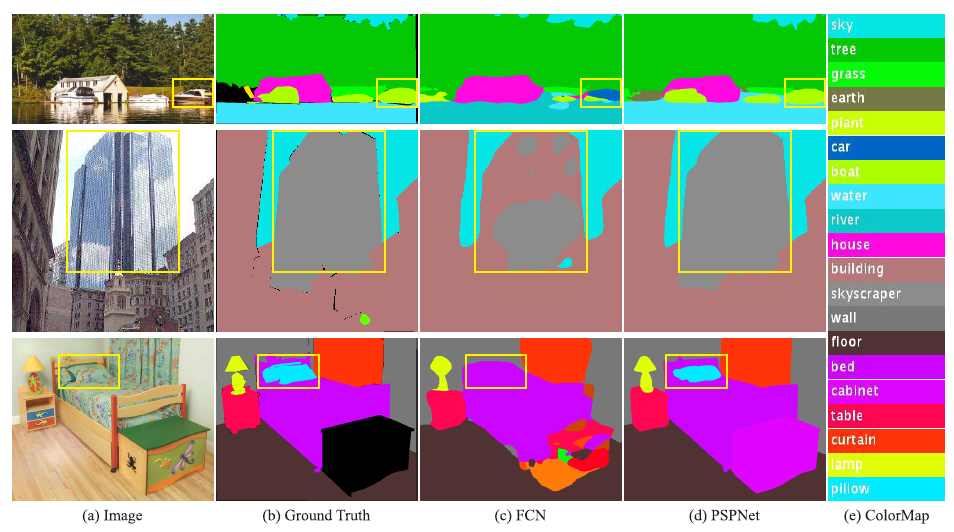
Figure 2. Scene parsing issues we observe on ADE20K [43] dataset. The first row shows the issue of mismatched relationship – cars are seldom over water than boats. The second row shows confusion categories where class “building” is easily confused as “skyscraper”. The third row illustrates inconspicuous classes. In this example, the pillow is very similar to the bed sheet in terms of color and texture. These inconspicuous objects are easily misclassified by FCN.
- boat 의 그림이지만 비슷한 object인 car 로 인식 → 잘못 인식하였다. why? 비슷하게 생겨서, 따라서 주변 환경을 고려하는 것이 필요(더 global한 정보)
- skyscraper 와 building 을 구별하지 못하고 섞여 있다. 이런 문제를 categories들 간의 relationship을 사용해 해결할 수 있음
- 이불과 같은 무늬를 가진 베개를 구별하지 못함. pillow 란 class가 눈에 띄지 않아서 찾지 못하였음
3.1 Important Observations
세 가지 문제점을 다시 살펴보겠습니다.
1. Mismatched Relationship
예를 들어, 비행기 같은 경우는 도로가 아니라 하늘을 날고 있는 경우가 더 많을 것이고 위의 figure 2 예시처럼 차로 잘못 인식된 보트도 사실 물 위에 있기 때문에 보트로 인식하는 것이 더 적절합니다.
이런 contextual한 정보의 부족이 misclassification할 가능성이 더 높아집니다.
Context relationship은 특히 복잡한 scene을 이해하는데 중요합니다. 비주얼적인 패턴이 비슷한 경우가 많기 때문입니다.
2. Confusion Categories
ADE20K dataset에는 헷갈릴만한 class의 쌍이 많습니다.
- field and earth
- mountain and hill
- wall, house, building and skyscraper
위의 경우 class들은 거의 외관으로 흡사합니다. 실제로 해당 데이터셋 전체적으로 17%의 pixel error를 가진다고 합니다. 위의 figure 2에서 FCN은 skyscraper와 building의 일부를 인식하고 box를 그립니다. 이 결과는 결국 둘 다 정답이 될 수 없고, 이러한 문제는 카테고리들 사이의 관계를 활용하여 해결할 수 있습니다.
3. Inconspicuous classes
figure 2에서 베개도 비슷한 외관을 가져 발견되지 못했는데, 만약 global scene category를 무시한다면 베개를 찾는 것이 어려울 것입니다. 이를 개선하기 위해 여러 가지 크기의 sub-regions을 설정하고 각 sub-region의 global contextual information을 사용하면 눈에 잘 띄지 않는 object/stuff도 잘 찾을 수 있을 것입니다.
Scene에서 object와 stuff는 임의의 사이즈를 가집니다. 가로등(streetlight)과 표지판(signboard)같이 작은 사이즈의 객체는 어디에 있는지 찾는 것이 어렵습니다. 반대로 큰 객체는 FCN의 receptive field를 초과해려 연속적이지 않은 예측을 야기합니다.
- Solution : global information and contextual relationship
3.2 Pyramid Pooling Module
- 딥러닝에서는 receptive filed의 크기가 우리가 얼마나 많은 context information을 사용할 수 있는지를 대략적으로 알려줍니다.
- CNN은 receptive filed의 크기가 고정되어 있어 global scenery priro을 통합하지 못한다는 한계가 존재
- Global average pooling은 이미지 분류 task에서 global contextual prior로 좋은 베이스 모델이 될 수 있지만, 조금 복잡한 이미지의 경우에서는 중요한 정보를 모두 고려하기 역부족이다.
- why? Scene image엔 많은 object/stuff가 있으나 이를 바로 single vector로 만들어버리면 spatial relation을 잃고, 모호하게 만든다.
- 방법: pyramid pooling module
- 다양한 카테고리를 구별할 수 있게 도와주는 sub-region context를 포함하는 방법
- hierarchical global prior을 통해 각 다른 scale과 sub-regioin에 따른 정보를 포함할 수 있다.
구조를 조금 더 자세히 살펴보겠습니다.
- four different pyramid scales → 위치에 따른 pooling을 생성할 수 있음
- 1x1 convolution을 사용해 1/N으로 차원 축소 (N은 pyramid의 level size를 말함)
- Bilinear interpolation을 통해 원본 feature map의 크기로 upsampling 진행
- 그러면 Pooling → 1 x 1 convolution → bilinear interpolation을 거친 각 feature의 크기는 입력 feature map과 같아지므로 concatenation이 가능해짐
- 원본 feature map에 concatenate를 진행
sub-region
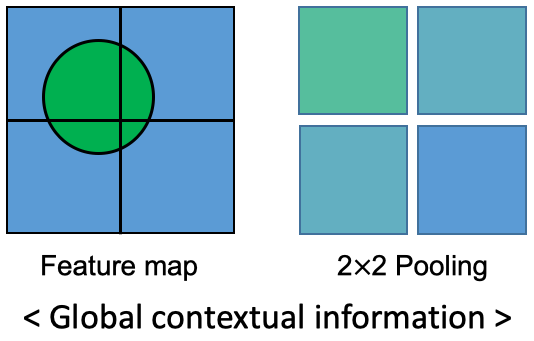
이미지 출처: https://intuitive-robotics.tistory.com/50
Circle 모양의 Feature를 가진 Feature map을 4개의 sub-region으로 나눕니다. 나누어진 각 sub-region에 존재하는 pixel 값들을 Average Pooling을 통해 2×2 배열에 입력됩니다.
그 후엔 <Global contextual information>과 같이 각 sub-region의 전체적인 특징이 나타낼 수 있습니다.
즉, 위 figure 2에서 보았던 예시와 같이 자동차 또는 보트 모양의 local contextual information이 있을 때, 근처가 물이었기 때문에 물의 특징이 포함되어 평균을 구한 global contextual information이 형상과 주변 상황까지 함께 고려하여 Segmentation에 더 좋은 성능을 기여합니다.
1/N
Pooling을 통해 얻은 N개의 채널을 convolution을 이용해서 1/N로 줄입니다. 이는 마지막에 각 feature map을 upsampling하고 concatenation할 때 local과 global의 비율을 5:5로 맞추기 위함입니다.
추가 정리
- pyramid level과 각 level에 따른 size는 조정할 수 있습니다. (pyramid level = 4, size = 1x1 … etc)
- feature map의 사이즈는 pyramid pooling layer와 관련 있습니다.
- 이 네트워크는 작은 stride를 통한 pooling kernel로 different sub-region을 구성하게 됩니다.
- 그러므로 multi-stage kernel은 representation에 reasonable gap을 유지시켜줍니다. (gap은 global average pooling을 의미하는듯)
3.3 Network Architecture
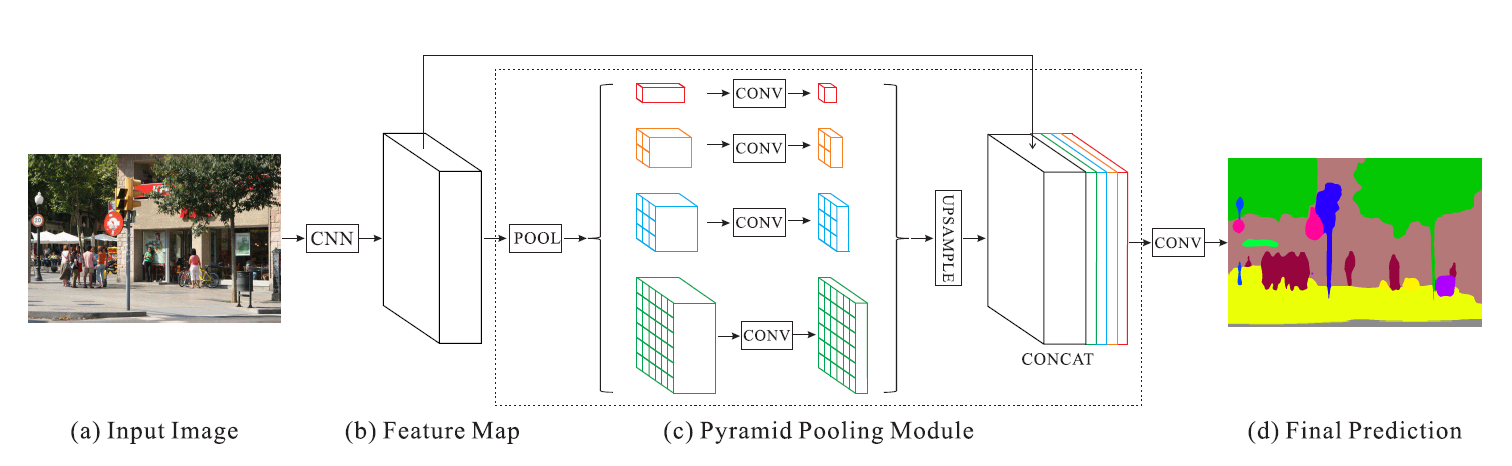
Figure 3. Overview of our proposed PSPNet. Given an input image (a), we first use CNN to get the feature map of the last convolutional layer (b), then a pyramid parsing module is applied to harvest different sub-region representations, followed by upsampling and concatenation layers to form the final feature representation, which carries both local and global context information in (c). Finally, the representation is fed into a convolution layer to get the final per-pixel prediction (d).
과정 간단 요약 (반복되는 내용)
- (a) Input image가 들어온다.
- CNN을 사용해서 (b) 마지막 conv layer의 feature map을 얻는다.
- feature map은 1x1, 2x2, 3x3 and 6x6의 4가지 다른 크기의 pooling을 통해 max(or average)를 계산하고 1x1xN, 2x2xN, 3x3xN, 6x6xN의 크기를 가진 sub-region이 만들어짐
- 마지막으로 이걸 upsampling하여 기존의 feature에 concat하여 마지막 conv layer에 전달. 최종 pixel별 예측을 얻음
PSPNet 전체적 구조
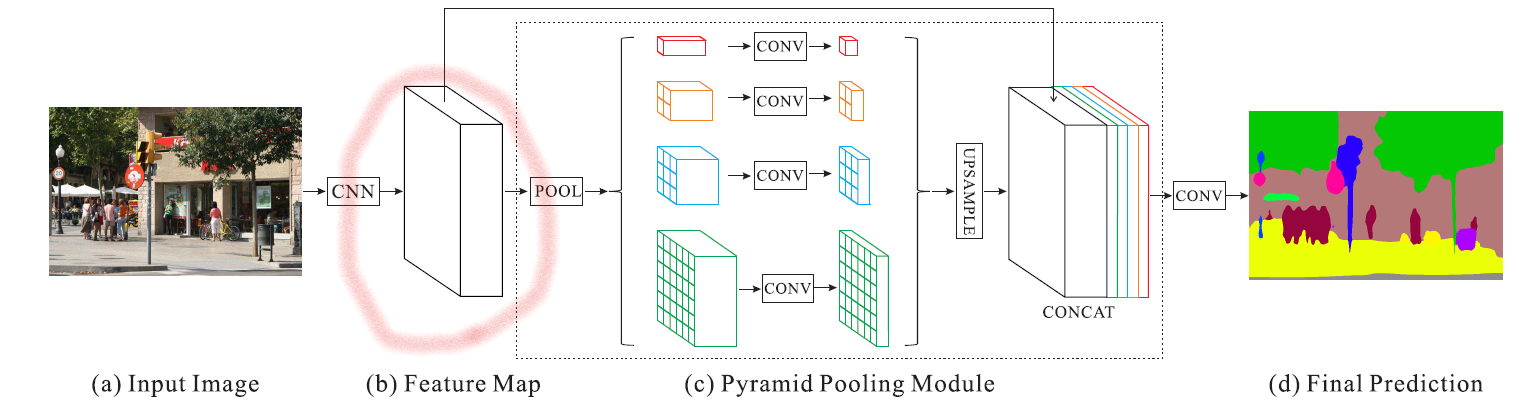
- Pre-trained ResNet (figure3-(b))
- Dilated convolution 사용
- input image → feature map 생성 → pyramid pooling module로 전달
- feature map의 output size는 input image의 1/8이 됨
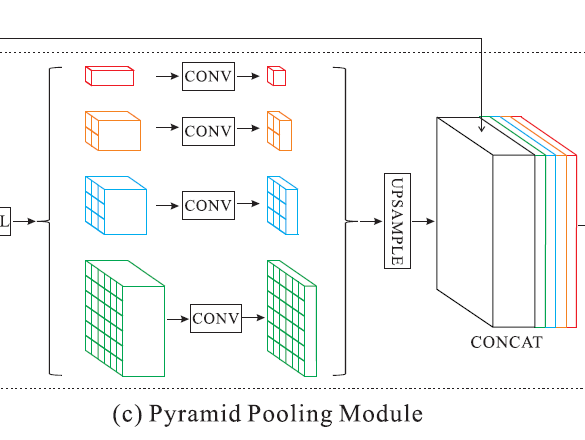
- Pyramid pooling module (figure3-(c))
- Global scene prior로서 여러 level에서의 context 정보 추출
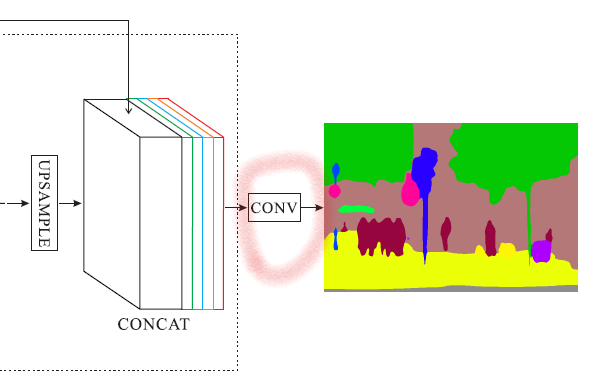
- Final convolution layer (figure3 between (c) and (d)
- Pyramid pooling module의 결과를 받아서 최종 prediction map 생성
4. Deep Supervision for ResNet-Based FCN
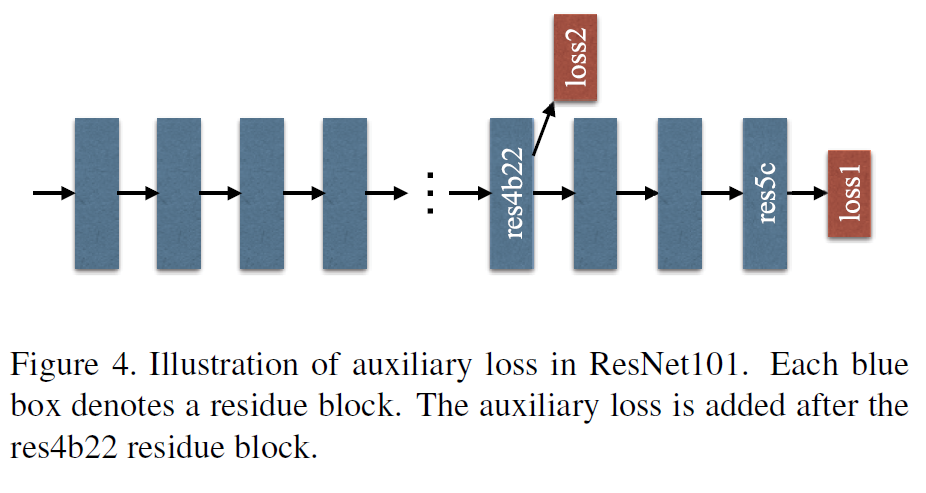
ResNet은 2가지 loss를 통해 optimization 수행
- Master branch loss
- softmax loss
- 더 많은 responsibility (weight 0.6)
- Auxiliary loss (보조 loss)
- softmax loss
- 더 적은 responsibility (weight 0.4)
해당 내용에 대해서는 잘 몰라서 더 찾아보았습니다.
보조 손실에 대한 아이디어는 GoogleNet에서 나왔다고 합니다. 동일한 모듈을 많이 쌓아 네트워크를 구축한다고 가정했을 때, 깊어질수록 gradient 소실 문제로 학습 속도가 느려지는 문제에 직면하게 됩니다. (BatchNorm 등장 이전)
각 모듈 계층에 대한 학습을 촉진하기 위해 해당 모듈의 출력에 작은 네트워크를 연결합니다. 이 네트워크에는 일반적으로 FC와 최종 분류 예측이 뒤따르는 몇 개의 변환 계층이 있습니다.
이 보조 네트워크의 작업은 최종 네트워크가 예측하는 것과 동일한 레이블을 예측하지만 모듈의 출력을 사용합니다. 이 aux 네트워크의 손실을 전체 네트워크의 최종 손실에 1 미만의 값으로 가중치를 추가합니다.
예를 들어, GoogLeNet에서 오른쪽 끝에 주황색 노드로 끝나는 두 개의 타워 같은 aux 네트워크를 볼 수 있습니다.
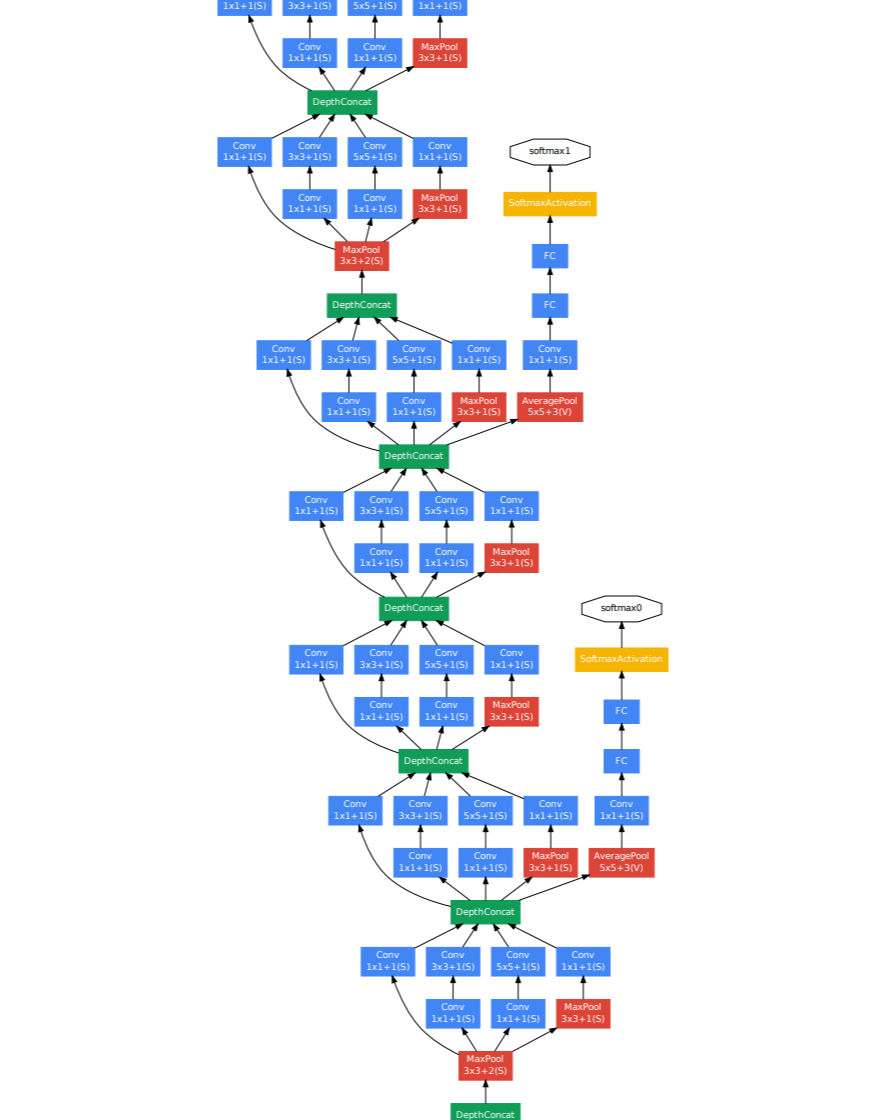
모듈이 천천히 학습하는 경우, 큰 loss를 생성하고 해당 모듈에서 gradient 흐름을 이끌어서 더 아래로 전달될 수 있도록 돕습니다. 매우 깊은 네트워크의 훈련 때 유용하게 도움이 되고, BatchNorm을 사용하는 경우 가중치가 무작위 초기화가 되어 초기 주기 동안 훈련을 가속화할 수 있습니다.
결론
- 보조 손실(Auxiliary loss)은 역전파(backpropagation)하는 동안 기울기 흐름을 추가하여 기울기 소실을 줄이는데 도움을 줍니다.
- 깊은 레이어가 있는 네트워크에서 사용합니다.
- 기울기 소실 문제를 줄이는데 도움이 됩니다.
- 따라서 훈련을 안정화하고 정규화할 수 있습니다.
- Inference시 말고, 훈련용으로 사용할 수 있습니다.
5. Experiments
PSPNet은 다음의 3가지 dataset에서 평가하였습니다.
- ImageNet Scene Parsing Challenge 2016
- PASCAL VOC 2012
- Cityscapes
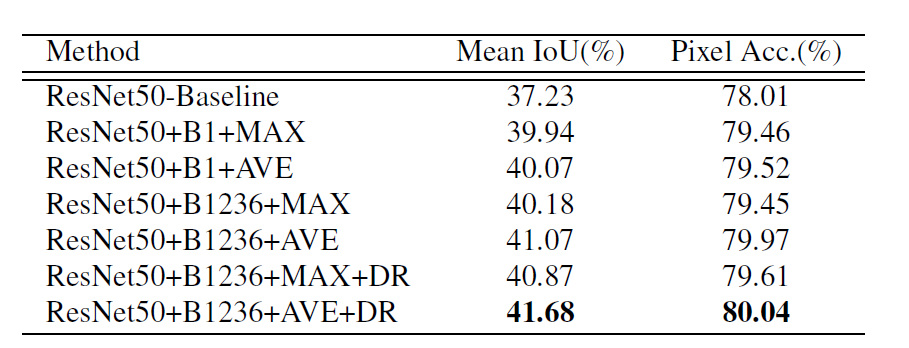
- table 1
- ResNet50 + B1236 (pooled feature maps of bin size) + AVE (average > max pooling) + DR (dimension reduction)
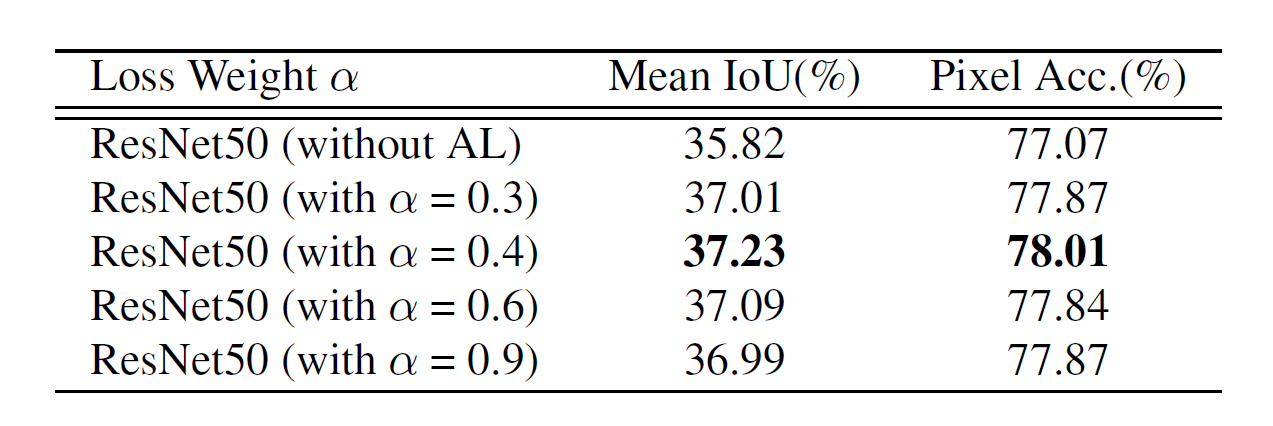
- table 2
- Segmentation 성능 지표인 Mean IoU와 Pixel Acc로 보는 Loss weight α에 따른 성능 결과 (Aux loss의 가중치 계수 alpha=0.4로 둘 때 가장 좋음)
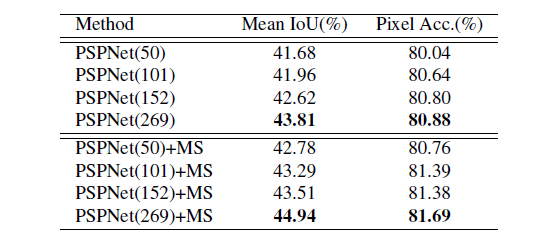
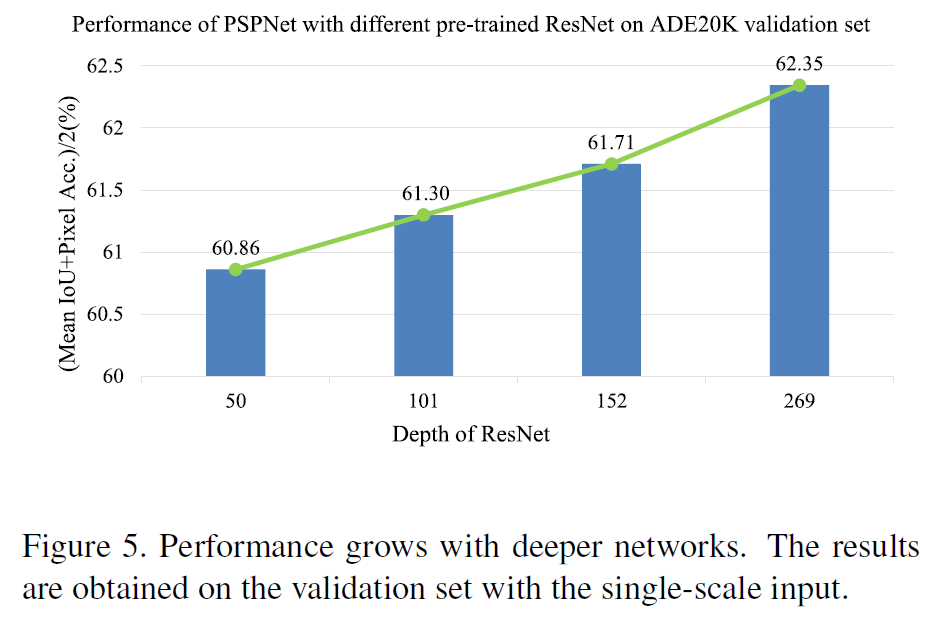
- table 3 and figure 4
- pre-trained model이 얼마나 깊어질수록 더 좋은 성과를 내는지 확인. ResNet의 깊이와 MS(multi-scale testing)가 더 좋은 결과를 보여줌
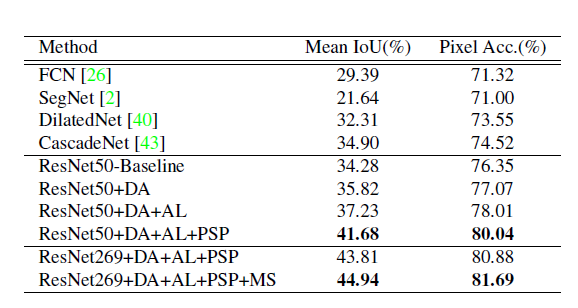
- table 4
- 따라서 다른 모델을 baseline으로 두었을 때랑 비교. 결론적으로 깊은 269층의 레이어를 가진 ResNet과 DA(Data augmentation), AL(Auxiliary loss), PSP(PSPNet), MS(multi-scale testing)이 합쳐진 것이 validation set에서 가장 성능이 좋았다.
최종적으로 PSPNet은 해당 Network를 형성한다.
→ ResNet269+DA+AL+PSP+MS




→ 더 정확하고 정교한 결과물을 확인할 수 있습니다.
해당 논문이 계속 보여주고 말하고 싶은 것은 결국 '우리는 FCN의 한계점들을 PSPNet에서 해결하였음!' 입니다.
6. Conclusion
PSPNet은 세그멘테이션을 위해 Feature map을 사용해서 얻었던 정보인 Local contextual information 뿐만 아니라 더 정교한 dense prediction을 위해 global한 정보를 얻고 싶었습니다.
그래서 Pyramid Pooling Module을 도입하였습니다. 해당 모듈에서 얻은 object/stuff의 주변 환경 정보인 Global contextual information을 또 다른 정보로 활용함으로써 Semantic Segmentation의 성능을 높였습니다.
기존의 feature map과 Pyramid pooling module로 나온 4가지 level의 feature map을 upsampling하여 합쳤습니다.
- PSPNet(Pyramid Scene Parsing Network)은 complex scene understanding에서 좋은 성능을 보입니다.
- Global pyramid pooling feature를 통해 추가적인 contextual 정보를 제공합니다.
- Deeply supervised optimization 방법을 통해 ResNet 기반의 FCN 네트워크를 학습합니다.
참조
1. 리뷰: https://gaussian37.github.io/vision-segmentation-pspnet/
2. 리뷰: https://intuitive-robotics.tistory.com/50
3. 리뷰: https://younnggsuk.github.io/2021/02/20/pyramid_scene_parsing_network.html
'Review > Paper' 카테고리의 다른 글
| [논문 리뷰] Attention Is All You Need (0) | 2023.01.04 |
|---|---|
| [논문 리뷰] Neural Machine Translation by jointly Learning to Align and Translate (0) | 2023.01.02 |
| [논문 리뷰] Automatic Data Augmentation for Generalization in Reinforcement Learning (0) | 2022.12.16 |
| [논문 리뷰] Batch Normalization: 논문으로 공부하고 이해하기 (0) | 2022.10.17 |
| [논문 리뷰] Deep Networks with Stochastic Depth (0) | 2022.08.21 |
- Total
- Today
- Yesterday
- 도커 작업
- 도커 컨테이너
- 파이썬
- 리눅스 나노 사용
- 리눅스 nano
- 도커
- prompt learning
- 파이썬 딕셔너리
- 파이썬 클래스 계층 구조
- support set
- stylegan
- 리눅스 나노
- 서버구글드라이브연동
- 구글드라이브연동
- 파이썬 클래스 다형성
- 퓨샷러닝
- Prompt
- Unsupervised learning
- NLP
- python
- 딥러닝
- 프롬프트
- style transfer
- clip
- few-shot learning
- linux nano
- docker
- cs231n
- CNN
- 리눅스
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |