NLP의 기초적인 내용, Encode-Decoder, Encoder Only, Decoder Only model 등에 대한 정리입니다. 잘못된 내용 있으면 지적 부탁드리고 참조는 아래 남겨두었습니다. 감사합니다.
- NLP tutorial
- Encoder-only Models(BERT)
- Decoder-only Models(GPT)
- Encoder-decoder Models (BART)
- In-Context Learning (GPT-3)
- Prompting for Few-shot Learning
Natural language processing
- Natural language processing
- Tokenization
- Word Embedding
1. NLP
- Giving computers the ability to understand text in much the same way human beings can.
- NLU (understanding)
- NLG (Generation)
Systems
1. Preprocessing
- Breaking up the input text into individual words or tokens. (tokenization)
2. Embedding
- Represent words in a numerical vector space.
3. Modeling
- Train the NLP system on a large corpus of text data, allowing it to make predictions and classify new text.
2. Tokenization
Examples

Padding

- Convert a sequence of characters into a sequence of tokens, i.e., meaningful character strings
3. Word Embedding
A representation that maps words to real-valued vectors
단어들을 특정 공간의 벡터 스페이스로 매핑 시키는 것, 의미론적으로 유사한 단어는 서로 가까운 공간 상에 위치하게 됨
- Bag-of-Words(BoW)
- A text is represented as the bag of its words
- The contents can be inferred from the frequency of words
- Vector representation does not consider the ordering of words in a document
- 단어들의 순서는 전혀 고려하지 않고, 단어들의 출현 빈도(frequency)에만 집중하는 텍스트 데이터의 수치화 표현 방법
- ex) John is quicker than Mary = Mary is quicker than John in Bow representation
- ex) One-hot encoding
- 특정 단어에 해당하는 인덱스일 땐 1, 나머지는 0으로 나타냄. 벡터로 표현할 수 있다는 장점이 있지만 단어간의 유사성이 보존되지 않음
- 이후에 나오는 Neural language model이 one-hot encoding의 저주를 해결한다
- Stopwords
- Words that do not carry any information
- Remove unnecessary information → Punctuation, Numbers, …
- Word2Vec
- Constructs words embeddings where words with similar context are embedded close to each other
- CBOW and Skip-gram models
- Center word and its context words
3. Skip-gram

- Rows in hidden layer weight matrix become word vectors(word vector look-up table)
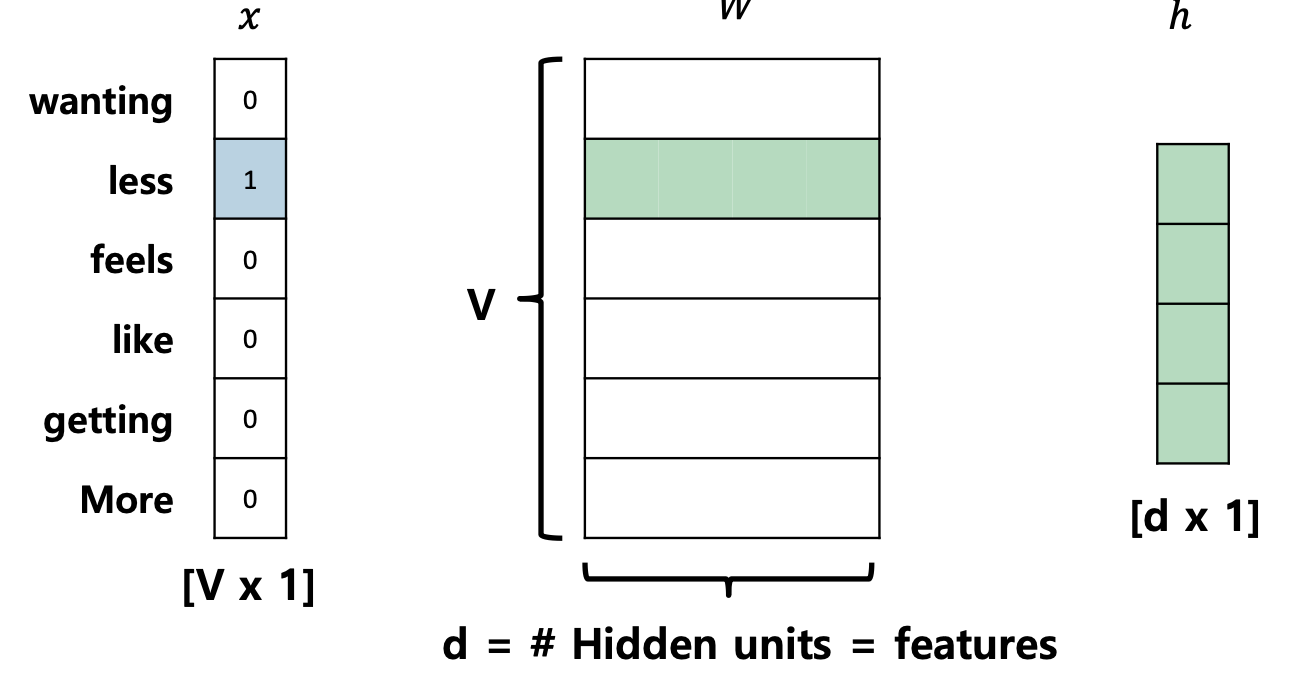
Summary
- Language Modeling: Task of understanding the probability distribution over a squence of words

- A language model computes a probability for a sequence of words: P(w_1, \dots, w_t)
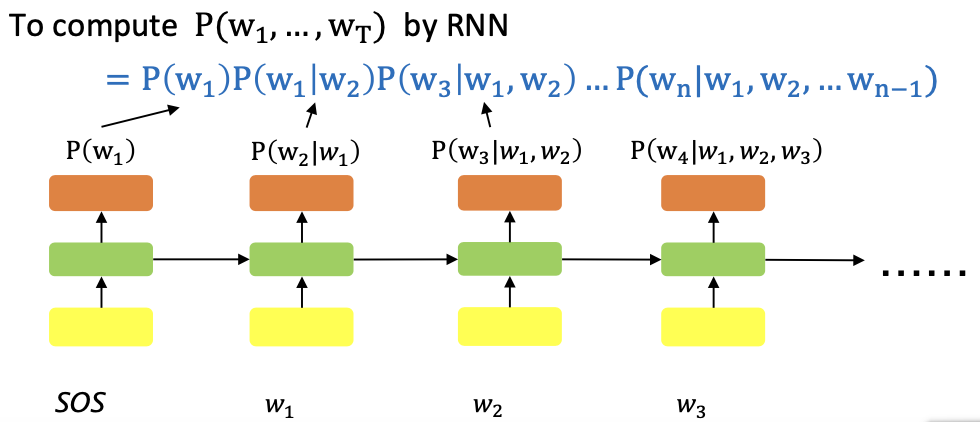
Language Modeling
- RNN
- Seq2Seq
- Attention
- Self-Attention and Transformer
- NLG
- NLU
- RNN
- Model sequential data
- Consider input sequence over discrete time
- Remember information in their hidden states for a long time
- Use the same weights at every time step
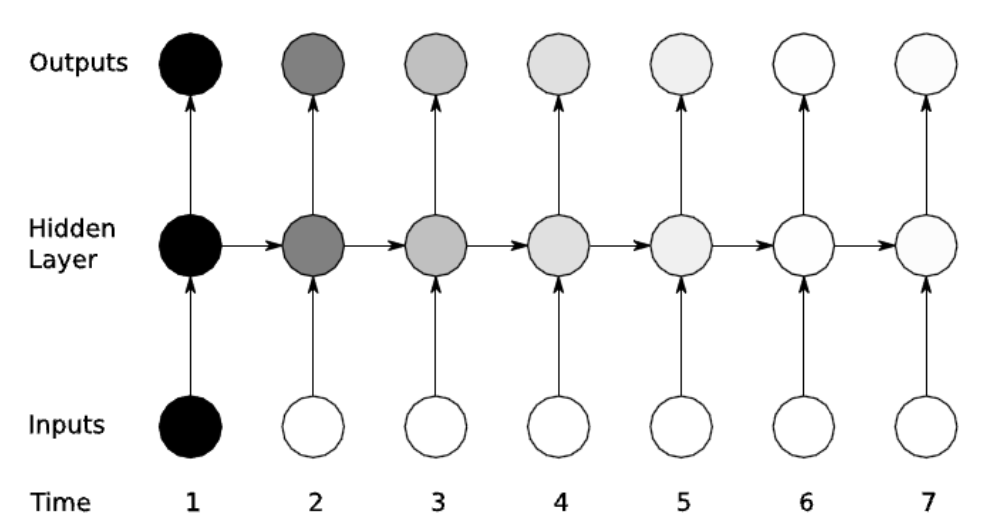
- Vanishing Gradients in RNN
- LSTM-RNNs
- LSTM can preserve gradient information
- 3 gates
- Input gate adjust the influence from input to cell
- Forget gate adjust the influence from cell to cell over time
- Output gate adjust the influence from cell to output
- Seq2Seq (Encoder-Decoder 구조의 모델)
- Seq2Seq with Attention (Decoding 과정에서의 Adaptive encoding)
- Transformer (Self-Attention Multi-head Attention)
2. Seq2Seq
Sourece sequence → Target sequence
- Machine translation / Dialog generation
- Parsing sentences into grammar trees
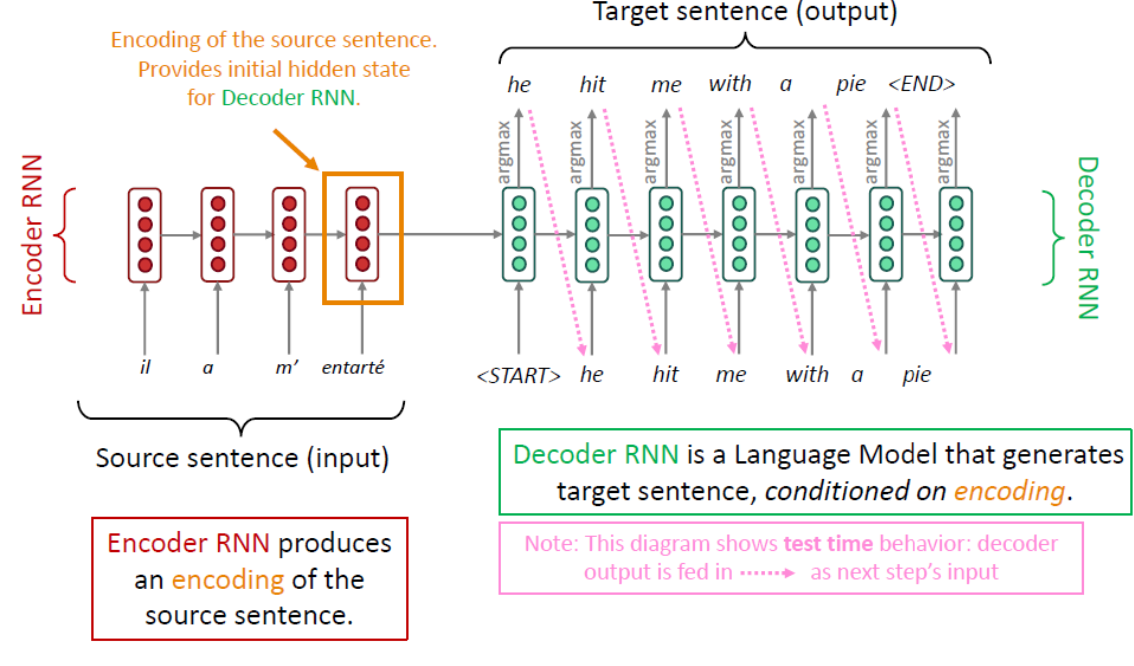
Seq2Seq Encoder-Decoder using RNN
- Encoder: from word sequence to sentence representation (a real-valued vector).
- Decoder: from representation to word sequence distribution
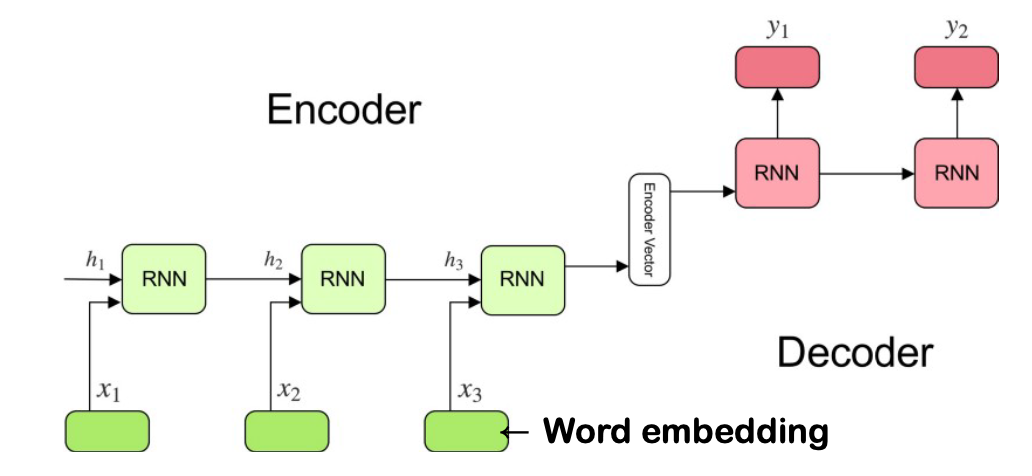
3. Attention
Motivation
- challenge in vanilla seq2seq for long sentence
- Decoder generates a translation solely based on the last hidden state.
- Information about the first word needs to be encoded in the last hidden state.
Attention Mechanism
- The decoder decides which different parts of the source sentence to pay “attention” at each step of the output generation.

- RNN hidden state of the decoder at $i$: $s_i=f(s_{i-1},y_{i-1},c_i)$
- The context vector $c_i$ is computed as a weighted sum of annotations $(h_1, \dots, h_T): c_i = \Sigma^T_{j=1} a_{ij}h_j$
- Attention weight $a_{ij}$: Alignment score function
- Scoring
- Alignment score function: $e_{ij}=score(s_{i-1},h_j)$ where $s_{i-1}$ is the RNN hidden state just before emitting $i$ th word, and $h_j$ is the $j$ th RNN hidden state of the input sentence.
- It scores how well the inputs around position $j$ and the output at position $i$ match

Normalization
- Let $a_{ij}$ be the probability that the target word $y_i$ is aligned to (or translated from) a source word $x_j$.
- $a_{ij}$ is computed by normalization the probabilities with a softmax.
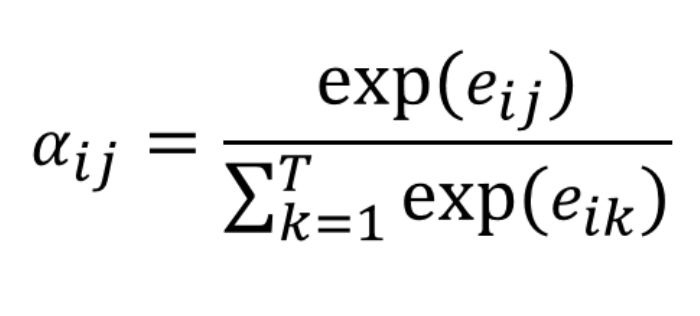
Limitation of RNN
- Vanishing gradient promblem
- Computationally expensive
- Difficult to train
- Very long gradient path
- Inability to process parallel sequences
- Can only process one input at a time
4. Self-Attention and Transformer
- Self-attention relates different positions of a single sequence.
- Each element in the sentence attends to other elements from the same sentence → context-sensitive encodings
- Self-attention enhances the automatic understanding of text
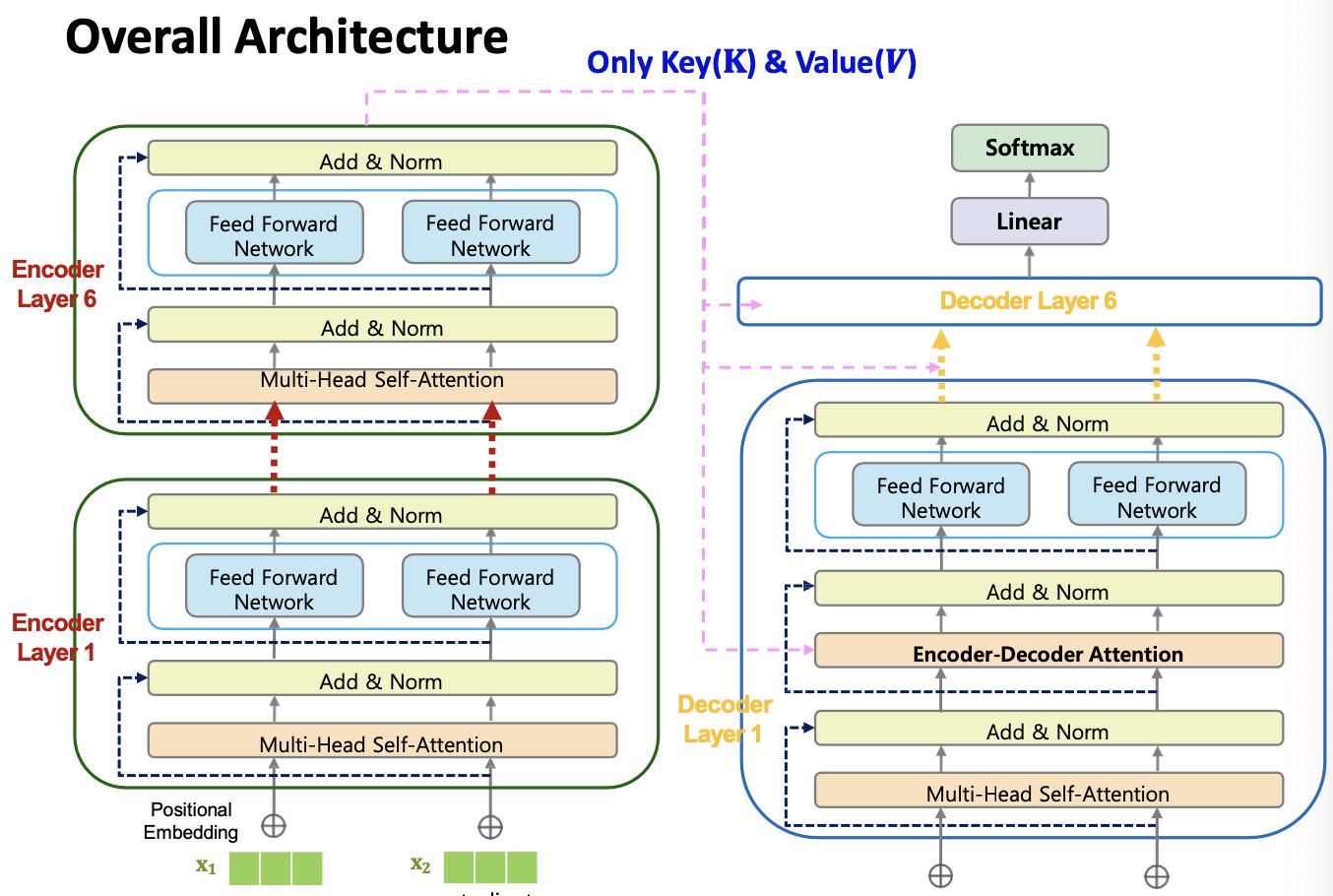
- An encoder-decoder structure
Model Overview of Transformer

a. Positional Embedding: To utilize the order of the sequnce
b. Encoder
Two sub-layers
(1) Multi-Head Self-attention
- The output of each sub-layer = LayerNorm($x$+sublayer($x$)) (x→ residual connection)
- All of the queries, keys, and values come from the out put of the previous layer ($Q=K=V$)
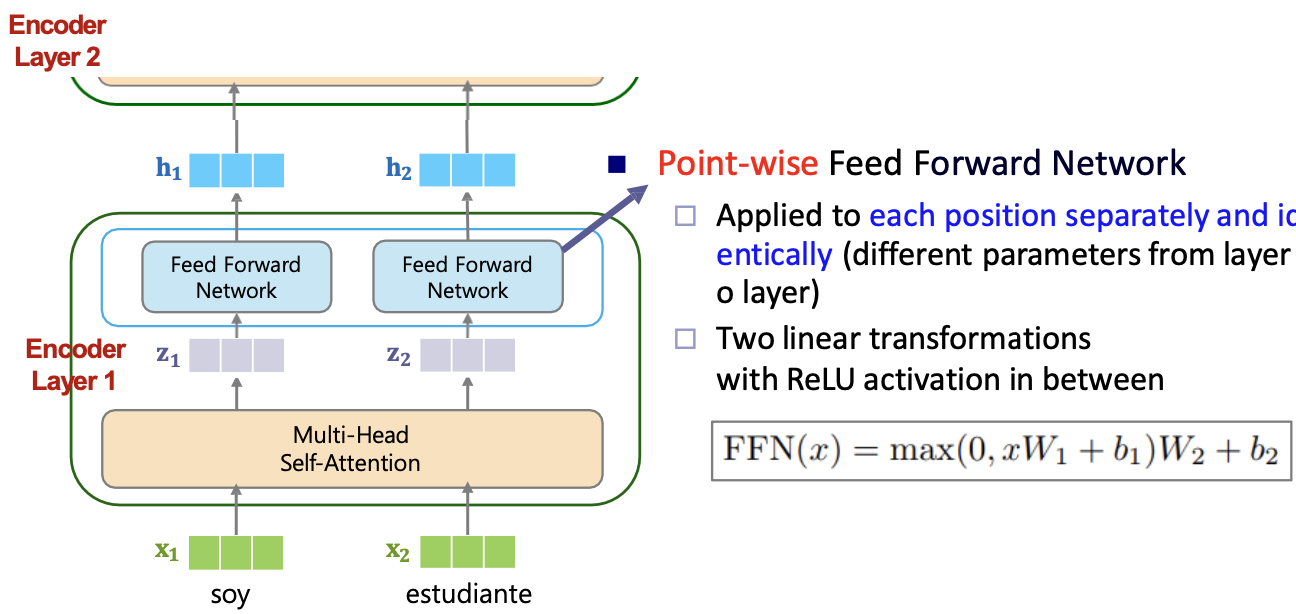
(2) Position-wise Feed Forward Network
c. Self-Attention(Scaled Dot-product Attention)
- Computing a representation of a sequence considering the relation ship between different positions
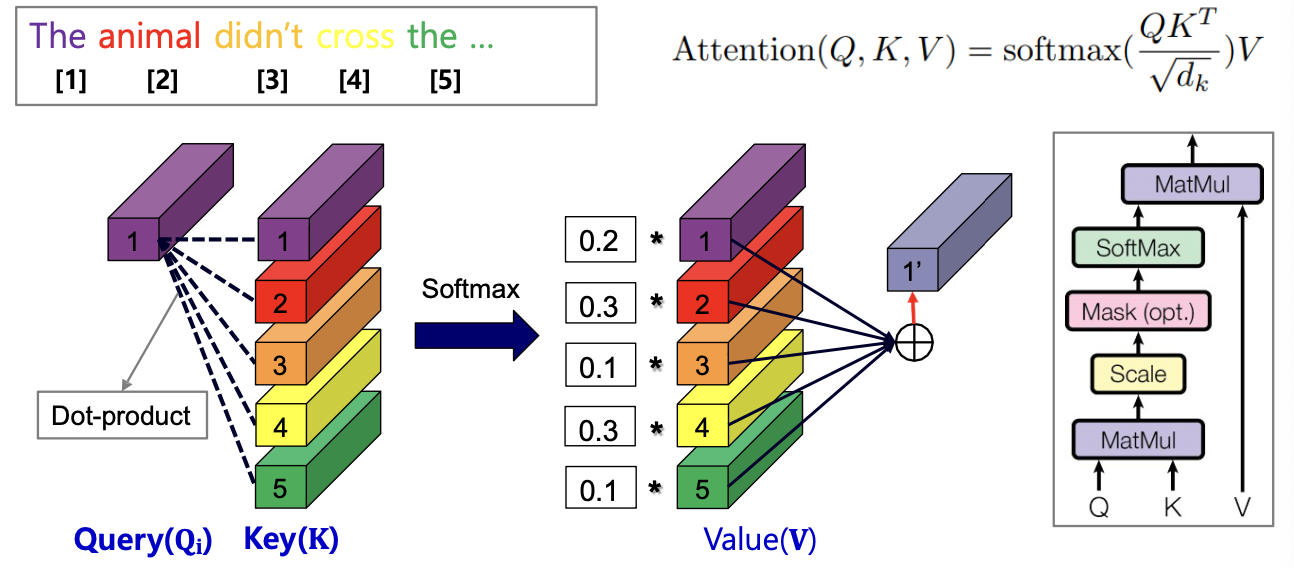
d. Multi-head Attention
- Apply the “Scaled Dot-Product Attention” several times with diffe rent linear projections

e. Encoder Architecture
f. Residual Connection

g. Decoder

h. Overall Architecture
5. NLG
- ex) Machine Translation, Summarization, Dialog System, Stroy Generation
- Training
- Train transformer using Cross entropy loss
- Inference
- Predict the next word
- Insert at the end of the sentence
- Used as the input of the GPT model
- Repeatedly predicting the next word
- Search Algorithm
- Greedy search just select the highest probability
- Beam search keeps the most likely num_beams of hypotheses at each time step and eventually choosing the highest probability path
- Evaluation Metrics: BLEU Score
- The higher is better
- Evaluates the similarity between tow sentences by counting matching n-grams

BLEU(Bilingual Evaluation Understudy) score란 성과지표로 **데이터의 X가 순서정보를 가진 단어들(문장)**로 이루어져 있고, **y 또한 단어들의 시리즈(문장)**로 이루어진 경우에 사용되며, 번역을 하는 모델에 주로 사용됩니다. 3가지 요소를 살펴보겠습니다.
- n-gram을 통한 순서쌍들이 얼마나 겹치는지 측정(precision)
- 문장길이에 대한 과적합 보정 (Brevity Penalty)
- 같은 단어가 연속적으로 나올때 과적합 되는 것을 보정(Clipping)
n-grams
Use the previous N-1 words in a sequence to predict the next word
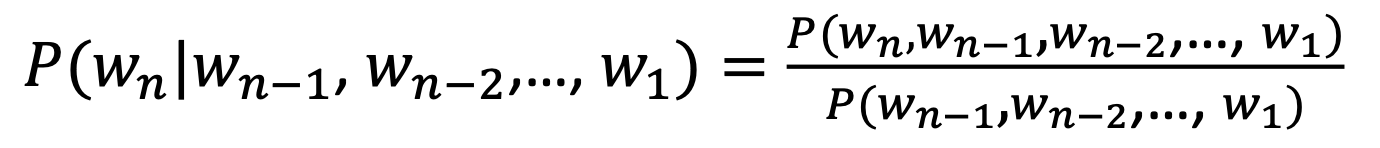
6. NLU
- ex) QA, Sentiment Analysis, Name Entity Recognition
Encodeer-only Models
BERT(Encoder-only Models)
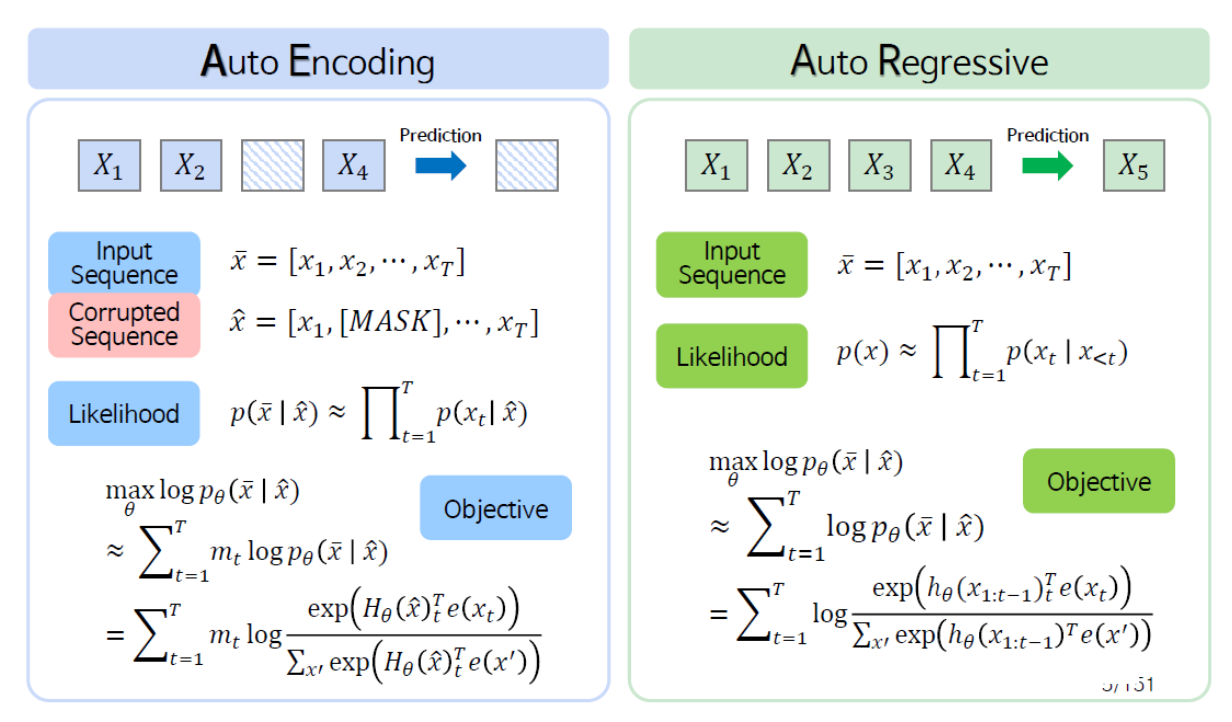
- Pre-training in NLP
- Pre-training Word Embeddings
- Pre-training Whole Model
- All (or almost all) parameters in NLP networks are initialized via pretraining.
- Pretraining methods hide parts of the input from the model, and train the model to reconstruct those parts.
- Pre-trained Language Models
- Train a neural network to perform la nguage modeling on a large amount of text.
- Save the network parameters
Pre-training / Fine-tuning Paradigm
Pretraining can improve NLP applications by serving as parameter initialization.
Step 1: Pretrain (on language modeling)
Lots of text; learn general things!
Step 2: Finetune (on your task)
Not many labels; adapt to the task!
- ELMO
- Train two separate unidirectional LMs (left-to-right and right-to-left) based on LSTMs
- Feature-based approach: pre-trained representations used as input to task-specific models
- Trained on single sentences from 1B word benchmark
- BERT: Bidirectional Encoder Representations from Transformer
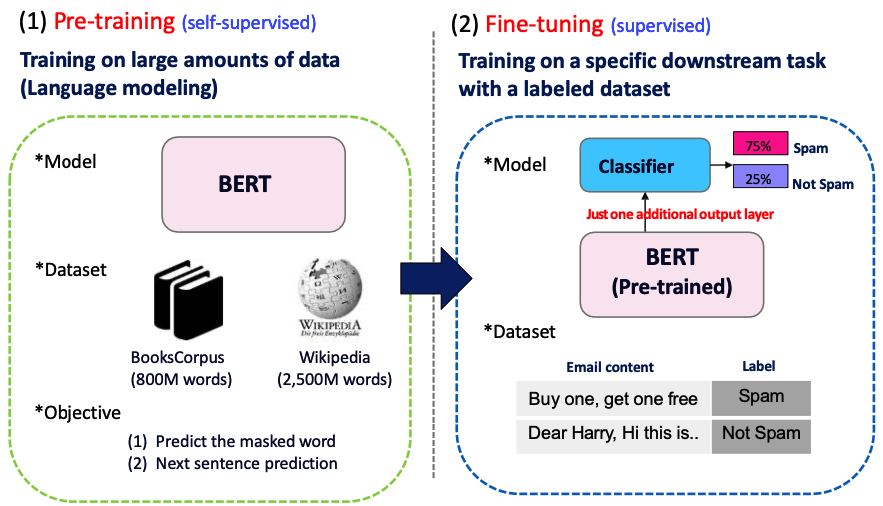
- Language model designed for bidirectional representation
- Pre-training and Fine-tuning approaches
BERT: Architecture
- BERT’s model architecture is a multi-layer Transformer encoder
- Multi-Head Self-attention
- Models bidirectional context
- Point-wise Feed-forward layers
- Computes non-linear hierarchical features
- Layer Normalization & Residual Connection
- Makes training deep networks healthy
- Positional embedding
- Allows model to learn relative positioning
Input Representation
Input representation is the sum of
- (1) Token embedding: WordPiece embeddings with a 30,000 token vocabulary
- (2) Segment embedding
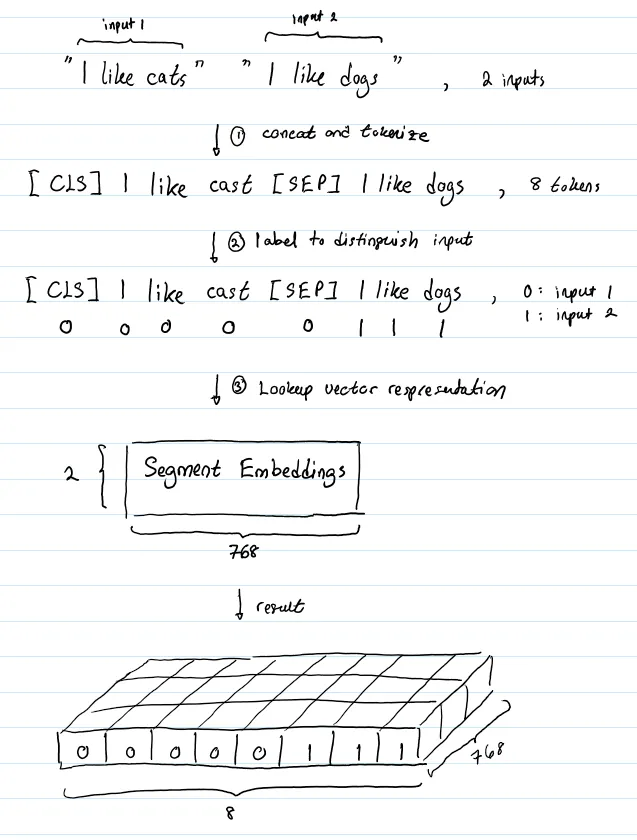
세그먼트 임베딩 레이어에는 2개의 벡터 표현만 있다. 첫 번째 벡터(인덱스 0)는 입력 1에 속하는 모든 토큰에 할당되고 마지막 벡터(인덱스 1)는 입력 2에 속하는 모든 토큰에 할당된다. 입력이 하나의 입력 문장으로만 구성되어 있다면, 세그먼트 임베딩은 세그먼트 임베딩 테이블의 인덱스 0에 해당하는 벡터일 뿐이다.
- (3) Position embedding: same as in the Transformer
- 단어의 벡터 표현인 shape (1, n, 768)을 가진 토큰 임베딩
- BERT가 페어링된 입력 시퀀스를 구별하는 데 도움이 되는 벡터 표현인 shape (1, n, 768)을 가진 세그먼트 임베딩.
- BERT가 공급되는 입력에 시간적 특성을 가지고 있다는 것을 알리기 위해 shape (1, n, 768)을 가진 임베딩을 배치
→ 이러한 representation은 shape (1, n, 768)을 가진 단일 표현을 생성하기 위해 요소별로 합산되고, 인코더 레이어에 전달되는 입력 표현이다.
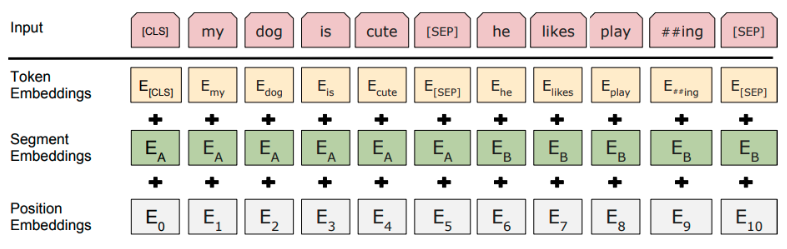
- Token Embeddings: WordPiece embeddings with a 30,000 token vocabulary
- Every sequence starts with [CLS] token
-
- [CLS]’s final state is used as the aggregate sequence representation for classification
-
- Input embedding = Elementwise-Sum(Position + Segment + Token) embedding
BERT: Subword Vocabulary: Byte Pair Encoding (BPE)
- 하나의 단어를 여러 서브 워드로 분리해서 단어를 인코딩 및 임베딩
- 단어들을 최소 단위(characters)로 쪼개서 빈도 수기반으로 병합하는 기법
- 워드피스(wordpiece)는 말뭉치에서 자주 등장한 문자열을 토큰으로 인식한다는 점에서 BPE와 본질적으로 유사
- 다만 어휘 집합을 구축할 때 문자열을 병합하는 기준이 다름
- 워드피스는 BPE처럼 단순히 빈도를 기준으로 병합하는 것이 아니라, 병합했을 때 말뭉치의 **우도(likelihood)**를 가장 높이는 쌍을 병합합니다.
→ OOV 문제 해결
→ Multi-lingual shared embedding: 같은 알파벳을 공유하는 경우 임베딩을 공유할 수 있다 → Low resource 언어 학습에 도움
*Out-of-vocabulary란?
자연어처리 모델 학습 데이터의 어휘 사전에 등록되어 있지 않은 단어를 미등록 단어 또는 OOV(Out of Vocabulary)라고 한다.
BERT!!!
- Designed to pre-train deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers
- Masked language model (MLM): bidirectional pre-training for language representations
- Next sentence prediction (NSP)
- Pre-trained BERT model can be fine-tunes with just one additional output layer to create SOTA models for a wide range of NLP tasks (QA, NER, Sentiment Analysis, etc)
BERT: Pre-training Tasks (1): Masked Language Modeling(MLM)
Task that enables the BERT model to learn bidirectional context information and grammars of the language
Methods
- 15% of each sequence are replaced with a [MASK] token
- Predict the masked words rather tan reconstructing the entire input in denoising encoder
- True labels can be easily obtained from the training data text corpus

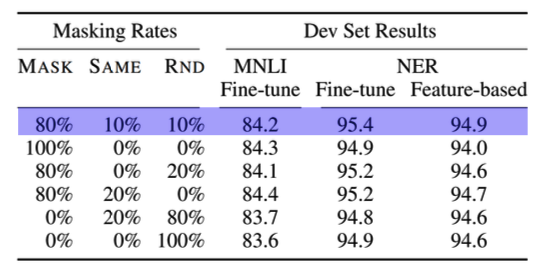
- A mismatch occurs between pre-training and fine-tuning, since the [MASK] token does not appear during fine-tuning
- (Solution) If the i-th token is chosen to be masked, it is replaced by the [MASK] token 80% of the time, a random toke 10% of the time, and unchanged 10% of the time
- (80%) my dog is hairy → my dog is [MASK]
- (10%) my dog is hairy → my dog is apple
- (10%) my dog is hairy → my dog is hairy
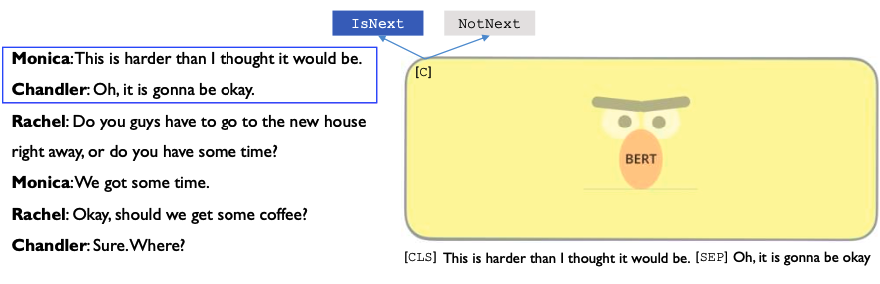
BERT: Pre-training Tasks (2): Next Sentence Prediction
- To learn relationships between sentences
- Binary prediction task that predicts whether Sentence B is the actual next sentence that follows Sentence A → True labels can be easily obtained from the training data
- text corpus
- Many important downstream tasks such as QA and NLI are based on understanding the relationship between two sentences, which is not directly captured by language modeling
- A Binarized next sentence prediction task that can be trivially generated from any monolingual corpus is trained
- 50% of the time B is the actual next sentence that follows A (IsNext)
- 50% of the time it is a random sentence from the corpus (NotNext)
- C is used for next sentence prediction
- ▪ Despite its simplicity, pre-training towards this task is very beneficial both QA and NLI
▪A mismatch occurs between pre-training and fine-tuning, since the [MASK] token does not appear during fine-tuning
▪(Solution) If the i-th token is chosen to be masked, it is replaced by the [MASK] token 80% of the time, a random toke 10% of the time, and unchanged 10% of the time
- (80%) my dog is hairy → my dog is [MASK]
- (10%) my dog is hairy → my dog is apple
- (10%) my dog is hairy → my dog is hairy

BERT: Fine-tuning to specific task
After pre-training, BERT is fine-tuned to specific NLP tasks
- Fine-tuning method: Incorporate BERT
- with one additional output layer for prediction
- The pre-trained BERT model parameters remain the same
- Minimum architecture change: minimize the number of parameters needed to learn in the fine-tuning

Summarize
- Pre-training and Fine-tuning
- Pre-training Whole Model
- Subword Tokenizing
- Pre-training Method of BERT
- Downstream Tasks
T5 (Encoder-Decoder Models)
- BART: Bidirectional and Auto-Regressive Transformer
- (1) Corrupting text with an arbitrary noising function
- (2) Learning a model to reconstruct the original text
- Denoising autoencoder for pre-training sequence-to-sequence models
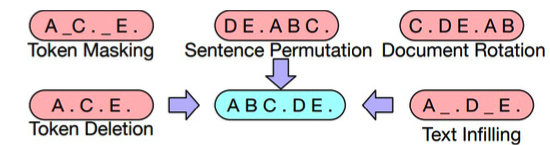
Original text (document): [A] [B] [C] [.] [D] [E] [.]
(1) Token Masking: [A] [M] [C] [.] [M] [E] [.]
- BERT와 똑같은 방식으로 masking 한 후 [MASK] 토큰이 원래 무엇이었는지를 예측
(2) Token Deletion: [A] [C] [.] [E] [.]
- 임의의 토큰들을 삭제하고, 삭제된 토큰들의 위치를 예측
(3) Text infilling: [A] [M]→ BC [.] [M]→ D [E] [.]
- Poisson 분포($\lambda=3$)로부터 span length를 샘플링
- span length만큼 연속된 토큰을 샘플링하여 하나의 [MASK] 토큰으로 대체
- [MASK]가 대체하고 있는 토큰 개수(span length)를 예측
(4) Sentence Permutation: [D] [E] [.] [A] [B] [C] [.]
- 문장의 순서를 랜덤하게 셔플
(5) Document Rotation: [C] [.] [D] [E] [.] [A] [B]
- 임의의 토큰을 랜덤하게 선택(시작 토큰)
- 시작 토큰을 중심으로 문서 회전
- 시작 토큰이 무엇인지 찾아내도록 학습
2. T5 (Text-to-Text Transfer Transformer)

Unified Framework for All Downstream Tasks
- BERT: Fine-tune different instances of the pre-trained model on different downstream tasks
- T5: Using the same model, same loss function, and the same hyper-parameters on all the NLP tasks (due to text-to-text framework)
- 즉, task에 상관없이 같은 objective를 통해 모델 학습이 가능
Text-to-Text
- Taking text as input and producing new text as output
- This framework provides a consistent training objective both for pre-training and fine-tuning → Maximum likelihood objective (regardless of the task)
장점으로 모든 NLP task에서 동일한 model/loss/hyperparameter를 사용 가능하다.
(1) Text-to-Text
모델의 크기만 커질 수 있다면 Text-to-Text 프레임워크는 Task-specific 모델과 비슷하거나 혹은 더 나은 성능을 보임
(2) Model architecture
→ Text-to-Text framework에서 Encoder/Decoder only 모델에비해 Encoder-Decoder 모델이 더 높은 성능을 보임
→ Encoder-Decoder가 파라미터를 공유하는 경우에도 성능 저하가 크게 나타나지 않음


(3) Pre-training objectives

(4) Pre-training dataset size
→ Pre-training 데이터의 크기는 클수록 좋음
→ 모델이 클수록 작은 사이즈의 데이터에 overfiting 되는 경향이 굉장히 큼
→ Memorize! 실험 모델 기준,학습되는 동안 약 64번 이상 같은 샘플을 볼 경우 발생
(5) Training strategies
→ Fine-tuning 할 때, 모든 파라미터를 추가적으로 학습하는 경우가 가장 성능이 좋음
(6) Scaling
- Small model trained on more data > Large model trained for fewer steps
- Ensemble models that we refine-tune from the same base pre-trained model < Pre-training and Fine-tuning all models completely separately
Model Description
- Encoder-Decoder model
- Objective
- span-corruption objective
- Longer training
- Multi-task Pre-training
- Example-proportional mixing
- Probability of sampling an example from the m-th task
- Beam search
3. UniLM: Unified Language Model
리뷰: UniLM Review
- Unified Pre-training: cloze-style tasks for language model(LM) pre-training
아이디어:
- BERT(bidirectional) /GPT(left-to-right)
- →다른objective task를위해모델구조가바뀜
- → 하나의 모델로 모두 통합해보자!
- → 어떻게? Self-attention mask 활용하자!
Unified Fine-tuning
- UniLM 모델은unidirectional decoder, bidirectional encoder, sequence-to-sequence model 등의 Objective 스타일에 따른 모든 task 형태를표현할수있음
- → 하나의 모델이 understanding/generation 문제 둘 다 풀 수 있음
Unified Pre-training tasks
- Unidirectional LM
- The context of the masked word to be predicted consists of all the words on its left/right (like GPT, but using masked LM)
- Bidirectional LM
- The context consists of the words on both the right and the left (same as BERT)
- Sequence-to-sequence LM
- The context of the to-be-predicted word in the target sequence consists of all the words in the source sequence and the words on the its left in the target sequence
- 마스킹된 토큰을 예측하는 pre-training 테스크와 어텐션 마스킹 방식을 조합하여 3가지 Language Modeling Objective(Uni-directional, Bi-directional, Sequence-to-Sequence)를 학습
- 각 LM 테스크 사이의 파라메터와 모델 구조를 단일 Transformer로 통일함으로써, 여러 LM을 만들어야 했던 필요성을 완화
- 각 objective 사이의 파라메터 공유를 통해 컨텍스트를 여러 방향으로 이용할 수 있는 능력을 학습하고, 오버 피팅을 방지하여 일반화 능력을 향상
- NLU 테스크 뿐만 아니라 Sequence-to-Sequence LM으로써, 요약이나 질문 생성 등의 생성에 이용 가능
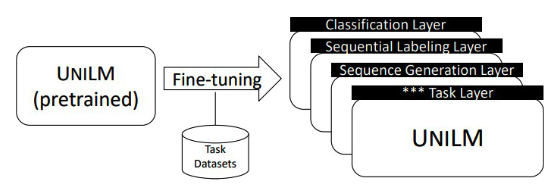
- Adding simple task-specific layers upon UniLM
- Fine-tuning several epochs on the downstream task
- Natural language understanding tasks (e.g., classification)
- Fine-tune UniLM as a bidirectional Transformer encoder
- Natural language generation tasks
- Fine-tune UniLM as a sequence-to-sequence model
4. BigBird: Transformers for Longer Sequences
- self-attention → fully-connected graph: self-attention을 각 token들의 linking으로 본다면 fully-connected graph로 표현할 수 있음
- fully-connected graph → sparse random graph: self-attention graph를 훨씬 더 크게, 그리고 sparse하게 만들면 훨씬 더 긴 sequence를 처리할 수 있으며 성능을 유지할 수 있음
- Transformers are ubiquitous but expensive!
- Requires $O(𝒏^𝟐)$ memory and compute
- Attention as graphs operations

- Do we need all the edges?
- Reducing complexity = Graph sparsification problem

Random graph
- Each edge is independently chosen with a fixed probability
- Information can flow fast between any pair of nodes

Random + Window + Global
- (Random + Window) attention = Not enough
Summarize
- Pre-trained Encoder-Decoder Models
- BART
- Denoising 기반의 Pre-training Objective
- T5
- 모든 task를 text-to-text
- UniLM
- Unified Language Modeling
- BigBird
- Sparse Attention
GPT & Hugging face
- GPT-1 : Improving Language Understanding by Generative Pre-Training
- GPT-2 : Language Models are Unsupervised Multitask Learners
- GPT-3 : Language Models are Few-Shot Learners

Language model meta-learning
- During unsupervised pre-training, GPT-3 develops a broad set of skills and pattern recognition abilities.
In-context learning
- Contrary to the traditional fine-tuning, GPT-3 does NOT change the model paramete rs for specific tasks
- Their few-shot setting uses several paired examples of the task in addition to t he task description
- Example of few-shot setting on the machine translation task: The model sees task description and a few examples of the task
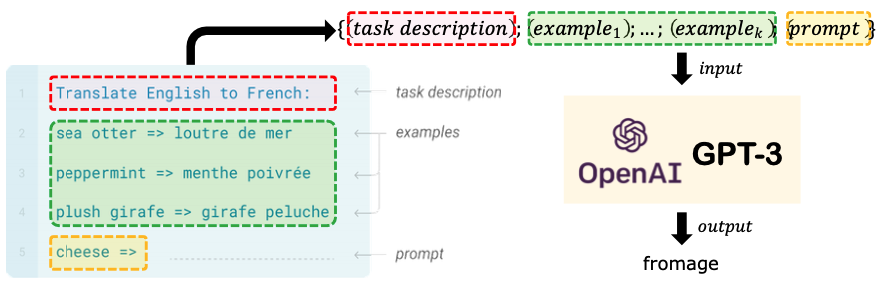


In-context Learning
Traditional Fine-tuning
- Model is trained via repeated gradient updates using a large corpus of ex ample tasks.
Limitations of Pre-training & Fine-tuning
- We still need large-scale task-specific datasets for fine-tuning
- Necessary to run separate models for each task
- Solution: scaling up based on scaling laws (Kaplan et al., 2020)

- Prompt: 테스트 입력 전에 오는 조건 텍스트
- Demonstrations: k-shot 훈련 데이터의 연결인 프롬프트의 특별 인스턴스
- Patter: 입력을 텍스트에 매핑하는 함수
- Verbalizer: 레이블을 텍스트에 매핑하는 함수

Prompting for Few-Shot Learning
- Adapting a Pre-trained Language Model
- Prompt-based Fine-tuning
- Small LMs are also Few-shot Learners
- How many data points is a prompt worth?
Head-based fine-tuning

Prompt-based fine-tuning

How to Design Good Prompts
- Manual Label Words: the Good and the Bad
- Manual Templates: the Good and the Bad
- Automatic Prompt Search
- Use 16 samples per class for both training (𝒟𝒟 train) and development (𝒟𝒟 dev) sets.
- Two methods for automatic prompt search.
- Automatic label word search (with manual templates)
- Automatic template search (with manual label words)
How to Design Good Prompts: Label Word
- Automatic Label Word Search
- Construct candidate sets
- 라벨이 있는 모든 training example이 주어졌을 때, 각 라벨에서 가장 높은 MLM 확률로 top-K words를 찾는다.
- Enumerate combinations and prune
- 모든 조합을 세고, D_train 제로샷 결과에 따라 가지치기 한다
- Re-rank by fine-tuning
- Fine-tune → 나머지 조합 / Re-rank by D_dev
How to Design Good Prompts: Prompt Ordering
Try different prompt orderings before taking any further actions.
- Proposed probing set construction method
- Discard the generated labels, as there is no guarantee that these generated
- labels are correct.
- Scoring each prompt based on the following metrics

+++) Calibration
- Majority label and recency biases cause GPT-3 to become biased towards certain answers and help to explain the high variance across different examples and orderings.
- Majority label bias: GPT-3 is biased towards answers that are frequent in the prompt.

- Recency Bias: the tendency to repeat answers that appear towards the end of the prompt.

- Common token Bias: tends to predict the token that is occurs more in the pretraining distribution.
- Model is biased towards predicting the incorrect frequent token "book" even when both "book" and "transportation" are equally likely labels in the dataset

How to Design Good Prompts: Template
- Automatic Template Search
- Use T5 out-of-the-box to generate template candiates
- Re-rank them based on performance on dev set after fine-tuning.
- → T5 takes a fill-in-the-blank pre-training objective.
- Use beam search with size 100 to get many templates.
How to Design Good Prompts: Demonstrations
- Selecting Demonstrations
- Select demonstrations that are semantically close to the input by cosine similarities between the input and all the training examples using a pre-trained sentence encoder
결과
- Automatic templates outperform manual template
- Choosing demonstrations based on similarity is effective
- However, automatic search still relies on either manual templates or label words
Summarize
- Adapting a Pre-trained Language Model
- Prompt-based Fine-tuning
- Small LMs are also Few-shot Learners
- Pattern Exploiting Training (PET)
- Iterative Pattern Exploiting Training (iPET)
- Prompting provide a benefit in data size
References
- 중앙대학교 이환희 교수님의 고급자연어처리 수업을 바탕으로 공부하며 정리한 자료입니다.
- Princeton University COS 597G: https://www.cs.princeton.edu/courses/archive/fall22/cos597G
- Stanford University CS234 https://stanford-cs324.github.io/winter2022/lectures
- 강필성 교수님 수업 자료: https://github.com/pilsung-kang/Text-Analytics
'AI > NLP' 카테고리의 다른 글
| Transformer Inference의 두 단계: Prefill과 Decode 및 KV Caching 차이 (0) | 2024.11.04 |
|---|---|
| Prompt-based Learning이란? (0) | 2023.04.22 |
| Embedding Layer의 이해 (0) | 2022.11.06 |
| Lecture 12: Recurrent Networks (RNN, LSTM, GRU) (0) | 2022.08.25 |
| RNN과 LSTM 기본 개념 이해하기 (0) | 2022.08.24 |




댓글