

티스토리 뷰
Justin Johnson의 Deep Learning for Computer Vision 강의로 Lecture 12: Recurrent Neural Networks 입니다.
이번 강의에서 다루는 내용은
- RNN, LSTM, GRU
- Language modeling
- Sequence-to-sequence
- Image captioning
- Visual question answering
입니다.
이중 RNN, LSTM, GRU 관련된 내용 위주로 다룰 것 같습니다.
Recurrent Neural Networks

RNN은 sequence를 진행하며 업데이트 해 줄 'internal state'를 갖고 있다는 것이 핵심 아이디어입니다.
모든 스텝마다 vector x의 sequence마다 recurrence formula를 적용하여 진행할 수 있습니다.
ht=fW(ht−1,xt)
그리고 같은 함수와 같은 파라미터 세트를 모든 스텝에서 사용합니다.
(Vanilla) Recurrent Neural Networks
state는 "hidden" vector h로 구성되어 있습니다.
첫 번째 hidden state는 모두 0에서 세팅되어 있고 학습을 시작합니다.


Backpropagation Trough Time

loss를 계산하기 위해 전체 sequence를 forward하고, gradient를 계산하기 위해 전체 sequence를 backward합니다.
이 방법의 문제는 긴 sequences는 너무 많은 메모리를 사용하게 된다는 점인데요.
그것 때문에 나온 방법이 Truncated Backpropagation Through Time입니다.
Truncated Backpropagation Trough Time

전체 sequence를 대신하여 sequence의 chunk를 통해 forward/backward합니다.

hidden states를 계속해서 forward해서 가져오지만, backpropagation의 경우엔 한 덩어리만큼 실행합니다.

마지막에 loss가 계산됩니다.
이제 Gradient가 계산되는 flow를 살펴봅니다.
Vanilla RNN Gradient Flow


ht=tanh(Whhht−1+WxxtXt+bn)
=tanh((whh whh) (ht−1xt) +bn)
=tanh(w (ht−1xt) +bn)
ht에서 ht−1의 W(실제로 WThh)의 곱들로부터 Backpropagation합니다.

h0의 gradient 연산은 W의 많은 factor를 포함합니다. (repeated tanh)
1. Largest singular value > 1 : Exploding gradients
2. Largest singular value < 1 : Vanishing gradients
1의 경우 Gradient clipping을 통해 해결할 수 있습니다. 각 norm들이 너무 큰 경우에 gradient를 scale합니다. 코드는 아래와 같습니다.
grad_norm = np.sum(grad * grad)
if grad_norm > threshold :
grad *= (threshold / grad_norm)
2의 경우 RNN architecture를 좀 손보면서 해결할 수 있습니다.
Long Short Term Memory (LSTM)
위에서 살펴보았던 Vanilla RNN은 아래와 같습니다.
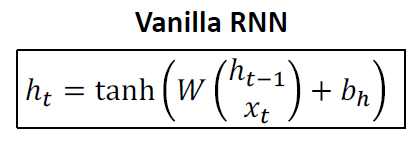

LSTM의 경우 각 timestep마다 두 vector가 있습니다.
- Cell state: ct∈RH
- Hidden state: ht∈RH
각 timestep마다 네 gates를 연산합니다.
- Input gate: it∈RH
- Forget gate: ft∈RH
- Output gate: ot∈RH
- “Gate?” gate: gt∈RH
- i: Input gate, whether to write to cell
- f: Forget gate, Whether to erase cell
- o: Output gate, How much to reveal cell
- g: Gate gate(?), How much to write to cell

it, ft, ot는 시그모이드에 곱해지고, 마지막 gt는 tanh에 곱해집니다.

Long Short Term Memory (LSTM): Gradient Flow



layer가 하나일 때

layer가 여러 개일 때

첫 번째 레이어에서 나온 hidden state를 다음 RNN의 input으로 전달합니다.

세 개 이상의 레이어가 있는 경우에서도 동일합니다.
Other RNN variants (GRU)
다른 RNN의 변형으로 GRU가 있습니다.
이는 statistical machine translation을 위한 RNN의 encoder-decoder를 사용한 구문 표현 학습입니다.

RNN Architectures: Neural Architecture Search

LSTM의 구조를 살펴볼 수 있습니다.
Summary
요약하면 아래와 같습니다.
- RNN은 architecture 디자인에 따라 많이 유동적입니다.
- Vanilla RNN은 단순하지만 효과적으로 잘 작동하는 것은 아닙니다.
- 보통 LSTM이나 GRU를 사용합니다. 이는 서로 상호작용을 추가해 gradient 흐름을 유지시킵니다.
- RNN에서 gradient의 역전파 흐름은 explode 되거나 vanish됩니다.
- Exploding은 gradient clipping으로 다룰 수 있습니다.
- Vanishing은 상호작용을 더해 다룰 수 있습니다. (→LSTM)
- 더 낫고 단순한 아키텍처는 현재 연구에서 주요 관심 분야입니다.
- 이론과 실증 모두 더 나은 이해가 필요합니다.
'AI > NLP' 카테고리의 다른 글
| [자연어처리 수업 정리] Natural language processing - tutorial (2) | 2023.04.20 |
|---|---|
| Embedding Layer의 이해 (0) | 2022.11.06 |
| RNN과 LSTM 기본 개념 이해하기 (0) | 2022.08.24 |
| LSTM(Long Short-Term Memory), GRU(Gated Recurrent Unit) 그림으로 이해하기 (2) | 2022.08.24 |
| RNN(Recurrent Neural Networks, 순환 신경망) 그림으로 이해하기 (2) | 2022.08.24 |
- Total
- Today
- Yesterday
- 프롬프트
- 리눅스 나노 사용
- 구글드라이브연동
- python
- 서버구글드라이브연동
- support set
- 파이썬 딕셔너리
- 리눅스
- docker
- stylegan
- CNN
- 도커 컨테이너
- linux nano
- 도커
- Unsupervised learning
- 퓨샷러닝
- 리눅스 나노
- 파이썬
- 파이썬 클래스 계층 구조
- 딥러닝
- Prompt
- cs231n
- few-shot learning
- 파이썬 클래스 다형성
- NLP
- style transfer
- prompt learning
- clip
- 리눅스 nano
- 도커 작업
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |