

티스토리 뷰
머신러닝 면접 기출 질문과 답변 정리 - Machine Learning Interview Questions and Answers
Suyeon Cha 2022. 5. 25. 14:53해당 게시글은 위 출처에서 질문과 답변을 참고하여 내용을 정리하였음을 밝힙니다.
Machine Learning Interview Questions and Answers
Q-1: 머신러닝이란 무엇인가요?
머신러닝은 인간처럼 행동할 수 있는 지능적인 시스템을 개발하는 알고리즘에 대한 연구입니다. 기계가 데이터를 학습하고 패턴을 인식하여 새로운 데이터가 도착하면 예측을 할 수 있도록 합니다.
Q-2: 지도 학습과 비지도 학습의 핵심 차이점은?


Supervised learning에는 label이 지정된 데이터가 필요하고, 맞춰야 하는 값이 있습니다. 따라서 크게 2가지로 나눌 수 있는데 첫 번째로는 예측하는 값이 categorical한 경우 분류(classification) 문제가 있습니다. 두 번째로는 예측하는 값이 continuous한 경우, 값을 예측하는 회귀(regression) 문제가 있습니다.

Unsupervised learning에는 label이 지정된 데이터가 없습니다. 따라서 데이터 포인트 세트 내에 존재하는 구조를 파악해야 합니다. 가장 대표적으로 데이터의 특성을 파악해서 묶는 Clustering이 이에 해당하며 대표적으로 k-means, DBSCAN, SOM 등 다양한 알고리즘이 존재합니다. 또한, 주요한 feature를 추출하는 dimensionality reduction 분야도 있습니다.
<Machine learning algorithms>

Q-3: 딥러닝과 머신러닝의 차이

머신러닝은 명시적으로 프로그래밍 되지 않은 작업을 수행하기 위해 알고리즘을 사용하여 데이터에서 학습하는 컴퓨터를 의미합니다. 딥러닝은 인간의 뇌를 모델로 한 복잡한 알고리즘 구조를 사용합니다. 이를 통해 문서와 이미지 및 텍스트와 같은 비정형 데이터를 처리합니다.
딥러닝은 머신러닝의 하위 집합인데요.
주요 차이점을 3가지로 정리할 수 있습니다.
첫 번째, 딥러닝은 Artifitial algorithms 구조를 사용한다는 점입니다.
두 번째, 더 큰 데이터가 필요합니다. 머신러닝은 수천 개의 데이터 포인트로 작동하지만 딥러닝은 수백만 개의 데이터 포인트에서 작동합니다. 복잡한 다층 구조로 이루어져 더 큰 데이터가 필요합니다. 따라서 상당한 computing 성능이 필요합니다.
세 번째, 딥러닝 알고리즘엔 인간의 개입이 훨씬 적다는 점입니다. 머신러닝의 경우, feature를 추출하고 classifier를 선택하여 알고리즘을 조정합니다. 반면 딥러닝 알고리즘은 feature가 자동으로 추출되고 알고리즘은 자체적으로 오류에서 출발합니다.
Q-4: Data mining과 machine learning의 차이점

데이터 마이닝이란 용어는 데이터를 마이닝하여 패턴을 추출하는 것에 해당합니다. 많은 양의 데이터에서 지식을 추출합니다. 머신러닝은 학습할 수 있도록 하는 알고리즘을 개발하는 연구입니다.
데이터 마이닝의 주요 목적은 비정형 데이터를 사용하여 미래에 사용할 수 있는 숨겨진 패턴을 찾는 것이고, 반면 머신러닝의 목표는 훈련 데이터에서 학습하고 테스트 데이터로 모델을 평가하는 것입니다.
Q-5: 인공 지능과 머신 러닝의 차이점
인공지능은 머신러닝보다 더 큰 개념입니다. 인공지능은 인간 두뇌의 인지 기능을 모방하고, AI의 목적은 알고리즘을 기반으로 지능적으로 작업을 수행하는 것입니다. 반면에 머신러닝은 인공지능의 하위 개념이며, 프로그래밍 되지 않고 학습할 수 있도록 머신을 개발하는 것이 목표입니다.
Q-6: 5가지 인기 있는 기계 학습 알고리즘
머신러닝 알고리즘을 선택할 수 있는 몇 가지 옵션이 있습니다. 시스템 요구 사항에 따라 적절한 알고리즘을 선택할 수 있습니다.
- 나이브 베이즈(Naive Bayes)
- 서포트 벡터 머신(Support Vector Machine)
- 의사결정 트리(Decision Tree)
- KNN(K-Nearest Neighbor)
- K-means
등이 있습니다.
Q-7: 머신 러닝과 빅데이터의 차이점
빅데이터는 대용량 데이터 세트(Big data라고 함)를 수집하고 분석하는 접근 방식입니다. 빅데이터의 목적은 조직에 도움이 되는 대용량 데이터에서 유용한 숨겨진 패턴을 발견하는 것입니다. 이에 반해 머신러닝은 명시적인 지시 없이 어떤 작업도 수행할 수 있는 지능적인 장치를 만드는 연구입니다.
Q-8: 의사결정나무의 장단점

Decision tree는 모든 내부 노드(Node)가 속성에 대한 '테스트(test)'를 의미합니다. 모든 분기가 테스트 결과를 나타내고, 각 리프(leaf) 노드가 클래스 레이블을 나타내는 순사도와 같은 구조를 가집니다. 루트(Root)에서 리프(leaf)까지의 경로를 분류 규칙이라고도 합니다.
- leaf node: 마지막 노드
- root node: 맨 위의 노드
- edge: 질문과 질문을 연결
의사 결정 트리는 그래프 구조를 갖고 있어서 이해하고 해석하기 쉽습니다. 또한, 결과 해석이 가능한 화이트박스 모델을 사용합니다. 다른 모델과 결합할 수 있습니다.
Q-9: Inductive Machine Learning and Deductive Machine Learning을 비교하여 설명
- Inductive: 귀납적
- Deductive: 연역적
연역적 머신러닝은 어떤 방식으로든 증명할 수 있는 지식을 학습하기 위한 알고리즘을 연구합니다. 문제 해결 속도를 높이기 위해 일반적으로 기존 지식을 활용하여 연역적으로 지식을 추가하여 사용합니다.
귀납적 학습의 관점에서 본다면 어떤 입력 샘플 $x$가 있을 때, 더 구체적으로 일반화해서 새로운 샘플을 더 쉽게 추정할 수 있도록 직면하는 문제입니다.
Q-10: 신경망의 장단점

신경망의 주요 장점은 많은 양의 데이터셋을 처리할 수 있다는 점입니다. 종속 변수와 독립 변수 간의 복잡한 비선형 관계를 감지합니다. 신경망은 거의 모든 다른 기계 학습 알고리즘을 능가하기도 하지만 단점도 존재합니다.
단점은 블랙박스와 같은 특성으로 Neural network가 특정 출력을 제공할 때마다 왜 해당 출력을 제공했는지 방법과 이유를 알지 못합니다.
Q-11: 분류 문제에 적합한 기계 학습 알고리즘을 선택하는 데 필요한 단계
첫째, 데이터, 제약 조건 및 문제에 대해 파악해야 합니다.
둘째, 어떤 알고리즘을 사용해야 하는지 결정하기 위해 어떤 유형과 종류의 데이터가 있는지 이해해야 합니다.
마지막으로 사용 가능한 머신러닝 알고리즘을 찾아 구현합니다.
이와 함께 grid search, random search, bayesian optimization 방식 등을 사용하여 하이퍼 파라미터를 최적화합니다.
Q-12: Training Set과 Test Set의 차이
머신러닝에서 학습에 사용되는 데이터가 training set이고, 이를 검증하기 위해 사용하는 데이터가 test set입니다.
Q-13: 과적합(Overfitting)이란?

머신 러닝에서 training set에만 맞게 모델이 학습된 경우를 과적합이라고 합니다. 이는 모델이 training set의 세부 정보와 노이즈를 획득하여 너무 복잡한 모델을 만든 경우인데요. 새 데이터에서도 중요한 데이터라 인식해버려 잘 맞지 않는 현상을 말합니다.
반대로 과소적합은 너무 단순한 모델을 생성해서 training data와 잘 맞지 않을 때를 말합니다. 모델의 복잡도를 늘려줌으로써 문제를 해결해야 합니다.
Q-14: 해시 테이블이란?
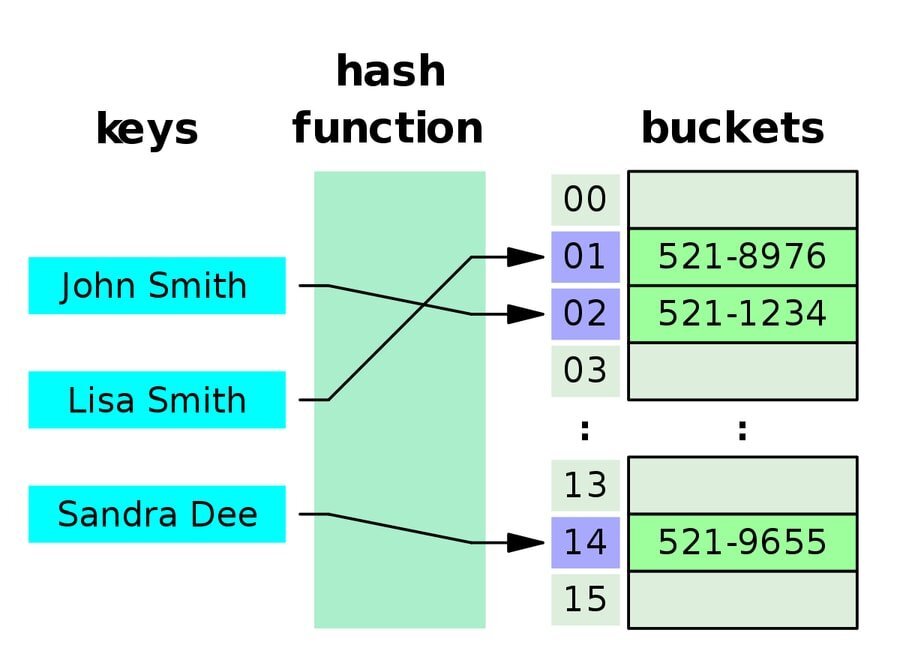
해시 테이블은 각 데이터에 고유한 인덱스 값이 있는 정렬된 배열로 데이터를 쌓는 데이터 구조입니다. 즉, 데이터는 연관 방식으로 저장됩니다.
이것은 데이터 구조의 크기가 중요하지 않음을 의미하므로 이 데이터 구조에서 삽입 및 검색 작업이 매우 빠르게 작동합니다. 인덱스를 슬롯 배열로 계산하기 위해 해시 테이블은 해시 인덱스를 사용하고 거기에서 원하는 값을 찾을 수 있습니다.
Q-15: 경사하강법이란?

경사하강법은 모델의 매개변수를 업데이트하는데 사용됩니다. 함수를 가장 단순한 형태로 최소화할 수 있는 최적화 알고리즘입니다. 여기서 최소화하는 함수는 손실 함수로 이 값이 최소가 될 때의 매개변수 값이 최적화 된 값입니다.
그러나 일반적인 문제의 손실 함수는 매우 복잡합니다. 매개변수 공간이 광대하여 어디가 최솟값이 되는 곳인지 짐작할 수 없습니다. 이런 상황에서 기울기를 잘 이용해 함수의 최솟값을 찾으려는 것이 경사하강법입니다.
주의할 점은 기울기가 가리키는 곳이 정말 함수의 최솟값인지 보장할 순 없습니다. 따라서 경사하강법은 현 위치에서 기울어진 방향으로 일정 거리만큼 이동하며 기울기를 계속해서 구하고 또 그 기울어진 방향으로 나아가는 것을 반복합니다.
따라서 경사하강법이 함숫값을 최소로 줄이는 방법이고 머신러닝을 최적화하는 알고리즘이라고 설명합니다.
Q-16: Backpropagation(역전파)란?

역전파(Back propagation)은 각 노드에 손실 정보를 전달하는 과정을 말합니다. 손실 정보는 Output layer에서 Input layer의 방향으로 이동하여 역전파라는 이름이 붙었습니다.
역전파 과정에서 사용하는 미분 규칙으로 chain rule(연쇄법칙)이 있습니다. 합성 함수의 도함수를 각 함수의 돟마수의 곱으로 나타내는 방식이며, 해당 법칙을 사용하여 손실 함수 $L$을 전달합니다.

역전파는 이 과정을 신경망의 모든 노드에 대해 실행하며, 이를 반복하면서 각 노드의 가중치(weight), 손실값(loss), 결정 경계(decision boundary)가 변합니다.

Q-17: confusion matrix란 무엇인가요?
머신러닝에서 분류(classification) 문제의 성능을 측정할 때 사용합니다. 해당 테이블은 예측값(predicted value)과 실제값(true value)의 네 가지 조합으로 구성됩니다.
1이 정답이고 0이 틀린 경우라고 한다면,
- TP(True Positives): 1인 레이블을 1이라 하는 경우
- 정답을 정확하게 분류
- FN(False Negatives) : 1인 레이블을 0이라 하는 경우
- 정답을 정답이 아니라고 잘못 분류
- FP(False Positives) : 0인 레이블을 1이라 하는 경우
- 정답이 아닌데 정답이라고 분류
- TN(True Negatives): 0인 레이블을 0이라 하는 경우
- 정답이 아닌 것을 정답이 아니라고 정확하게 분류
그리고 이 네 가지의 값을 바탕으로 여러 가지 척도로 평가할 수 있습니다.
- Accuracy(정확도)
- Precision(정밀도)
- Recall(재현율)
등이 있고, 이를 활용한 ROC curve, AUC도 있습니다.
Q-18: 분류와 회귀의 차이점
분류의 경우 예측해야 하는 출력값이 정수 값의 형태인 범주형이거나 불연속형인 경우에 해당됩니다. 회귀의 경우는 예측해야 하는 출력값이 수치적이거나 연속적인 경우에 해당합니다.
예를 들어, 스팸 메일을 분류하는 것이 스팸 메일과 스팸이 아닌 메일의 분류 문제이고 일정 기간 동안의 주식 가격을 예측하는 것이 회귀의 문제입니다.
Q-19: A/B Test?
A/B 테스트는 두 개의 모두 동일한 조건에서 독립 변수 A와 B만 다르게 설정하여 랜덤하게 시행되는 실험입니다. 예를 들어, 두 가지 버전의 웹페이지를 비교하여 주어진 전환 목표에 대해 더 나은 실적을 내는 변형을 파악하기 위해 수행됩니다.
Q-20: Sigmoid function이란?
시그모이드 함수는 activation function 중 하나로 output에 non-linearity 성격을 줍니다.
$$\sigma(x) = \frac{1}{1+e^{-x}}$$

식과 그래프는 위와 같습니다.
y 값의 범위가 0에서 1로 z가 0일 때 0.5의 값을 임계값으로 같습니다. sigmoid function 같은 경우는 90년대 가장 인기 있는 activation function이었으나 현재는 잘 사용하지 않습니다.
그 이유로는
첫 번째, Vanishing gradient 문제입니다.

시그모이드 함수 같은 경우는 0과 가까운 값에서만 활성화되는데요. 값이 매우 크거나 작은 경우 0이나 1에 수렴하게 되고, 이를 saturated 된다고 표현합니다. 문제는 미분하면서 값이 점점 작아지면서 발생합니다.
두 번째는, not zero-centered입니다.

시그모이드 함수는 결괏값이 0이 중심이 아닌데요.

y 값의 범위가 [0, 1]이기 때문에 미분했을 경우 모두 0보다 큰 값을 가지게 됩니다. 이럴 경우에 수렴이 느리게 됩니다.
마지막으로, 지수 함수를 사용하여 연산 비용이 큽니다.
연산이 굉장히 큰 경우 성능 저하로 이어집니다.
Q-21: Convex function이란?
convex function은 연속 함수이며 주어진 영역의 모든 간격에서 중간점의 값은 간격 두 끝에서 값의 수치 평균보다 작다는 특징을 갖습니다.
Q-22: machine learning에 유용한 metric
- confusion matrix
- accuracy
- precision
- recall / sensitivity
- root mean square error
등이 있습니다.
Q-23: missing data를 처리하는 방법
모델을 개발하는 동안 누락도니 데이터를 처리하는 방법이 몇 가지 있습니다.
가장 쉬운 방법은 목록을 삭제하는 것입니다. 결측값이 있는 지정된 데이터를 모두 삭제하는 방법이고, 이 경우는 무작위로 누락된 데이터가 많을 경우에 사용됩니다.
두 번째는 평균값으로 대치하는 방법입니다. 다른 참가자의 평균을 취해 누락된 값을 채울 수 있습니다.
마지막으로는 평가 척도에 의해서 중간값이나 최빈값을 선택하여 대치할 수 있습니다.
Q-24: training set, validation, test set을 얼마나 쓸 것인가?
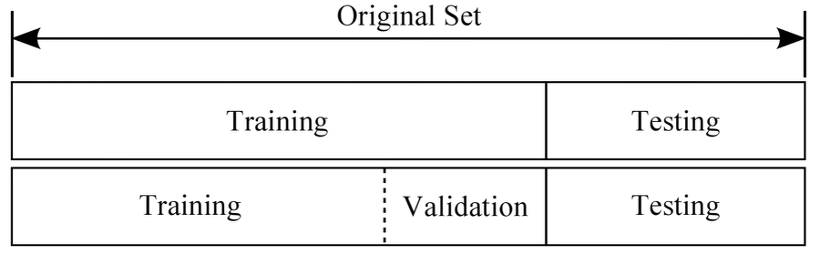
training set이 너무 작으면 variance가 높아지고, 마찬가지로 test set이 작게 만들어지면 모델 성능에 대해 신뢰할 수 없는 추정이 발생할 수 있습니다.
일반적으로 train/test set의 경우 8:2로 나누며, train/validation/test set은 6:2:2로 나눕니다.
Q-25: 차원 축소를 위한 몇 가지 특징 추출 기법을 언급하시오
- Independent Component Analysis
- Isomap
- Kernel PCA
- Latent Semantic Analysis
- Partial Least Squares
- Semidefinite Embedding
- Autoencoder
Q-26: Classification Machine Learning Algorithms 사용 예시
- 의료쪽으로 X-ray 사진 및 영상을 통해 종양의 여부를 따질 수 있다.
- 와인의 품종, 산도, 지역 등을 통해 등급을 나눌 수 있다.
- 키, 몸무게, 시력, 지병 등으로 군대 현역/공익/면제 등을 나눈다.
- 메일을 받았을 때 스팸인지 아닌지를 분류할 수 있다.
- 고기의 지방 함량, 지방색, 성숙도 등을 통해 소고기 등급을 나눌 수 있다.
독립변수에 해당하는 feature를 통해 종속변수인 target을 예측하고 분류하는 문제이다.
Q-27: F1-score를 정의
F-score의 식은

식을 다시 정리하면

이렇게 됩니다.
F1-score는 Precision과 Recall의 조화평균이며, 0.0에서 1.0 사이의 값을 가집니다. 해당 값은 높을수록 좋습니다.
Precision과 Recall이 서로 trade-off 관계여서 두 가지 지표를 모두 사용하고 싶을 때 F1-score를 이용합니다.
Q-28: Bias-Variance Tradeoff 관계에 설명

편향(Bias)이란 모델의 평균 예측과 예측하려는 올바른 값 간의 차이입니다. 편향이 높은 모델은 훈련 데이터에 거의 주의를 기울이지 않고 모델을 지나치게 단순화합니다. 따라서 항상 train/test data 사이에 높은 오류가 발생합니다.
분산은 주어진 data point에 대한 모델 예측의 가변성 또는 데이터 확산을 알려주는 값입니다. 분산이 높은 모델은 훈련 데이터에 많은 관심을 기울이고, 이전에 본적이 없는 데이터(unseen data)를 일반화하지 않습니다. 결과적으로 이러한 모델은 훈련 데이터에서 잘 수행되지만 테스트 데이터에서는 높은 오류율을 보입니다.

모델이 너무 단순하고 매개변수가 매우 적은 경우, 편향이 높고 분산이 낮을 수 있습니다.
반면에 모델에 많은 수의 매개변수가 있으면 높은 분산과 낮은 편향을 갖게 됩니다.
따라서 우리는 데이터를 과대적합하거나 과소적합하지 않고 적절하고 적절한 균형을 찾아야 합니다.

알고리즘은 동시에 더 복잡하고 덜 복잡할 수 없습니다. 낮은 분산과 낮은 편향이 가장 최상의 결과이며, 머신러닝의 궁극적 목표가 됩니다.
Q-29: K-means와 KNN에서 Manhattan Distance를 사용 못하는 이유

red(4,4)와 green(1,1)이 있을 때, 맨해튼 거리 측정법을 사용하여 거리를 계산해보겠습니다.

해당 식을 이용하면 $d=|4-1|+|4-1|=6| 입니다.
이 거리는 차원이 높은 경우 유클리드 거리보다 선호 되기도 합니다.

맨해튼 거리는 grid와 같은 경로에서 두 data point 사이의 거리를 계산하는데 사용합니다. 위처럼 수평 또는 수직으로만 거리를 계산하기 때문에 차수 제한이 있습니다.
반면에 Euclidean(유클리디안) metric은 모든 공간에서 거리를 계산하는데 사용할 수 있습니다. 데이터 포인트는 모든 차원에서 표시될 수 있으므로 다른 거리 metric보다 실행 가능한 옵션입니다.
둘을 비교하자면 맨해튼 거리는 축을 따라 이동하도록 제한돼서 유클리드 거리보다 더 멀리 이동합니다. 따라서 점 A와 점 B 사이의 유클리드 거리보다 더 짧을 수 없습니다.
Q-30: Decision tree을 Pruned 하는 방법
Pruning은 가지치기라고 합니다. 가지치기는 복잡도를 줄이고 예측의 정확도를 올립니다. error를 제거하고 cost 복잡성을 제거하면서 수행할 수 있습니다.
Decision tree는 root가 위에서부터 아래로 뿌리를 내려가는 구조입니다. 따라서 하부 트리를 제거함으로써 일반화 성능이 올라가고, 지나치게 overfitting하는 것을 막을 수 있습니다. 깊이가 줄어들고 결과의 개수가 줄어드는 효과가 있습니다.
크게 두 가지 방법이 있는데
첫 번째는, 트리의 깊이(depth)를 제한하는 방법과 leaf node의 최대 개수를 지정해놓는 방법이 있습니다.
두 번째는, 한 node에 들어가는 최소 데이터 수를 정해서 제한할 수 있습니다.
Q-31: Model Accuracy와 Model Performance 중 어떤 것이 필수입니까?
모델 정확도는 머신러닝 모델의 가장 중요한 특성이므로 모델 성능보다 중요합니다.
모델을 학습하는 과정에서 모델의 정확도를 신중하게 구축해야 하며, 점수가 매겨진 모델을 병렬화하고 분산 컴퓨팅하여 모델 성능을 항상 개선할 수 있습니다.
Q-32: 푸리에 변환을 정의
푸리에 변환은 입력으로 시간이 걸리고 파형을 구성하는 주파수로 분해하는 수학 함수입니다.
그것에 의해 생성된 출력은 주파수의 복소수 값 함수입니다. 푸리에 변환의 절댓값을 찾으면 원래 함수에 있는 주파수 값을 얻을 수 있습니다.
Q-33: KNN과 K-menas clustering의 차이
공통점으로는 둘 다 거리를 기반으로 구현되는 거리 기반 분석 알고리즘입니다. 차이점으로는 KNN은 지도 학습이며, K-means는 비지도 학습 알고리즘입니다.
KNN은 거리를 기준으로 주변에 가장 가까운 k개를 지정하여 찾고, K-means는 k개의 cluster를 찾아 군집화하는 알고리즘입니다.
따라서 label이 있고 없고의 차이에 따라 KNN의 목적은 classification이고, K-means는 clustering이 목적입니다.
Q-34: Bayes' Theorem 정의
베이즈 정리는 데이터라는 조건이 주어졌을 때의 조건부확률을 구하는 공식입니다. 베이즈 정리를 쓰면 데이터가 주어지기 전의 사전확률값이 데이터가 주어지면서 어떻게 변하는지 계산할 수 있습니다.
따라서 데이터가 주어지기 전 이미 어느 정도 확률값을 예측하고 있을 때 이를 새로 수집한 데이터와 합쳐 최종 결과에 반영할 수 있습니다. 데이터가 부족할 때 유용하게 쓸 수 있습니다.
즉, 베이즈 정리는 새로운 정보가 기존의 추론에 어떻게 영향을 미치는지를 나타냅니다.
Q-35: Covariance vs. Correlation
공분산(Covariance)은 두 개의 랜덤 변수 X, Y가 얼마나 많이 변할 수 있는지를 측정한 것입니다. 둘 사이의 선형 관계에 대한 정보를 알려줍니다.
공분산이 양수이면 두 확률 변수는 서로 양의 선형 관계가 있고, 음수라면 두 확률변수는 서로 음의 선형 관계에 있습니다.
변수의 스케일에 따라 값의 스케일이 달라지기 때문에 공분산이 크다고 상관관계가 더 강한 것은 아닙니다.
상관(Correlation)은 두 변수가 서로 얼마나 관련되어 있는지를 측정한 것입니다. 상관된 정도에 따른 절대적인 크기를 측정할 수 있도록 해줘서 그게 상관계수(Coefficient of Correlation)입니다. 따라서 공분산은 상관의 측도이고 상관은 공분산의 척도화된 버전입니다.
척도에 변화가 있어도 상관관계에는 영향을 미치지 않지만 공분산에는 영향을 미칩니다. 또 다른 차이점은 값에 있습니다. 즉, 공분산 값은 (-) 무한대에서 (+) 무한대 사이에 있는 반면 상관 관계 값은 -1과 +1 사이에 있습니다.
$$Cov(X,Y) = E[(X-\mu_x)(Y -\mu_Y)]$$
$$\rho_{X,Y} = Corr(X,Y) = \frac{Cov(X,Y)}{\sigma_X \sigma_Y}$$
Q-36. True positive rate와 Recall의 관계

True positive rate와 Recall은 같습니다. Recall이 실제 positive를 positive라고 예측한 비율을 의미하기 때문입니다.
$$Recall = \frac{TP}{TP+FN}$$

해당 표를 참고하여 Accuracy, Precision, Recall, False positive rate를 이해해보도록 합시다!
그외에 TNR(True negative rate), FPR(False positive rate), FNR(False negative rate) 등이 있습니다.
순서대로 실제로 negative를 negative라고 잘 예측한 비율, 실제로는 negative인데 positive라고 잘못 예측한 비율, 실제 positive인데 negative라고 예측한 비율을 의미합니다.
Q-37. 'Naive' Bayes가 'Naive'라고 불리는 이유
Naive bayes는 단순한 확률적 분류법을 사용하는 classifier입니다. 확률 모델에 베이즈 정리를 사용하여 유도되고, 실제로는 생길 수 없는 강한 독립 가정을 포함한다는 사실로부터 naive라는 말을 사용하였습니다.
여기서 말하는 강한 독립 가정은 데이터 요소의 특성 간에 강력한 독립성 가정을 의미합니다.
이는 지도 학습에 매우 효율적으로 훈련되며, 실제 응용에서는 parameter estimation을 위해 최대 우도(maximum likelihood)를 사용합니다.
Q-38. ROC curve를 정의

ROC 곡선은 TPR과 FPR을 plotting한 그래프로 분류 모델의 성능을 평가합니다.
- TPR(True positivee rate): 실제 positive를 positive라고 예측한 비율
- FPR(False positive rate): 실제로는 negative인데 positive라고 잘못 예측한 비율
곡선 아래의 영역은 AUC로 TPR은 크고 FPR은 낮을수록 좋으므로 회색의 영역이 왼쪽 위로 넓어지는 정사각형 모양이 가장 좋습니다. 따라서 너비 1이 될수록 좋습니다.
Q-39. Likelihood, Prior, Posterior 의미

- Prior Probability: 현재 가지고 있는 정보를 기초로 하여 정한 초기 확률
- Posterior Probability: 사건 발생 후에 어떤 원인으로부터 일어난 것이라고 생각되어지는 확률
- Likelihood: 결과에 따라 여러 가능한 가설을 평가할 수 있는 측도
Q-40. 연속형 변수와 범주형 변수 간의 상관 관계 측정 방법
상관 관계란 얼마나 밀접하게 관련된 두 변수가 선형인지를 측정하는 것입니다.
범주형 변수는 이산형이거나 제한된 양의 범주가 포함되어 있으며, 연속형 변수는 두 값 사이에 무한한 수의 값이 포함됩니다.
따라서 연속형 변수와 범주형 변수 간의 상관 관계를 측정하려면 범주형 변수의 수준이 2개 이하이어야 하고, 그 이상이면 안됩니다.
Q-41. 모델 정확도를 평가하기 위해 가장 자주 사용되는 metric 정의
분류 정확도는 모델 정확도를 평가하는데 가장 자주 사용되는 metric입니다. 전체 예측 샘플 수에 대한 올바른 예측의 비율이 얼마큼 되는지가 분류 정확도입니다.
Q-42. SVM은 언제 사용하나요?

서포트 벡터 머신은 분류와 회귀 문제를 해결하는데 사용할 수 있습니다.
Q-43. PCA에 회전이 필요한가요?
PCA는 특성들이 통계적으로 상관 관계가 없도록 데이터셋을 회전시키는 기술입니다. 원래 변수들 사이의 겹치는 정볼르 제거함으로써 변수를 줄입니다.
아직 이 부분에 대해선 이해가 덜 가서, 위키 백과의 내용을 빌려 왔습니다.
PCA는 본질적으로 평균 근방의 점들을 주성분들과 정렬하기 위해 회전시킨다. 이것은 직교 변환을 이용해 첫 번째 몇 개의 차원으로 분산을 가능한한 크게 한다. 따라서 남아있는 차원의 값들은 작은 값을 갖는 경향이 있고 최소한의 정보 손실만으로 차원이 줄여질 것이다. PCA는 종종 이런 식으로 차원 축소를 위해 사용된다.
AI 대학원 면접을 준비하면서 머신러닝의 기본 이론 개념을 정리해보았습니다!
많은 분들에게 도움이 되면 좋겠습니다.
'AI > Machine Learning' 카테고리의 다른 글
| 기초 확률, 가우시안 분포, 커널밀도추정, 최근접 이웃 접근법 (0) | 2023.04.27 |
|---|---|
| Data Science vs. Machine Learning - 공통점과 차이점 (0) | 2022.05.24 |
| [핸즈온 머신러닝] 챕터 9 비지도 학습 (clustering, k-means, DBSCAN, GMM) (0) | 2022.05.22 |
| [핸즈온머신러닝] 챕터 8 차원 축소 (0) | 2022.05.17 |
- Total
- Today
- Yesterday
- 도커
- 파이썬 클래스 다형성
- docker
- 파이썬 딕셔너리
- 리눅스 나노 사용
- stylegan
- 리눅스
- cs231n
- Prompt
- style transfer
- support set
- prompt learning
- Unsupervised learning
- 프롬프트
- 파이썬
- 퓨샷러닝
- 서버구글드라이브연동
- 도커 컨테이너
- 도커 작업
- 리눅스 nano
- CNN
- few-shot learning
- 딥러닝
- 구글드라이브연동
- 파이썬 클래스 계층 구조
- NLP
- 리눅스 나노
- clip
- linux nano
- python
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |