

티스토리 뷰

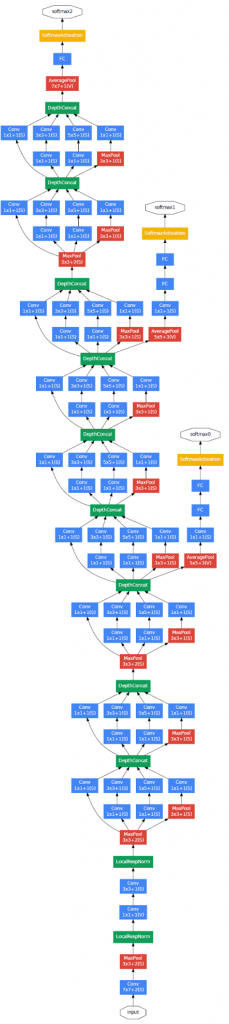
인셉션 모듈은 필터의 크기나 풀링을 결정하는 대신 그것들을 전부 다 적용해서 출력들을 다 엮어낸 뒤, 네트워크가 스스로 원하는 변수나 필터 크기의 조합을 학습합니다.
이렇게 설계하게 된 이전 모델들의 문제점으로는 큰 계산 비용 꼽았습니다.
5x5 filter로 예시를 들어 보면, 해당 필터 32개로 28x28x32의 출력이 나옵니다.
- input size: 28x28x192
- filter: 5x5x192, 32개
- output: 28x28x32
필요한 총 곱의 수는 각각의 출력 값을 계산하기 위한 곱의 수에다가 출력 값의 개수를 곱한 수가 됨. 이 모든 수를 곱하면 1억 2천만 정도가 됩니다.
→ 28x28x32 x 5x5x192 = 120m
1x1 conv는 1/10 정도로 연산을 줄입니다.
Using 1x1 conv
- input size: 28x28x192
- conv filter: 1x1x192, 16개
- output: 28x28x16
- conv 5x5x16, 32개
- output: 28x28x32
햐당 구조는 1x1을 사용해서 볼륨을 줄이고, 다시 5x5를 사용해 채널을 깊게 쌓습니다. 이런 구조를 bottleneck architecture라 합니다.
크기를 다시 늘이기 전에 줄이는 방법입니다.
첫 번째와 두 번째의 계산 비용을 배교해보겠습니다.
- 1x1 conv: 28x28x16 x 1x1x192 = 2.4m (240만)
- 5x5 conv: 28x28x32 x 5x5x16 = 10.0 m (1천만)
→ 총 1+2 만큼의 연산이 필요함. 1억 2천만에서 1천 2백만 개의 곱셈으로 줄인 셈이 됩니다.
신경망의 층을 구축할 때, 1x1, 3x3, 5x5, pooling layer 등 고민하기 원하지 않는다면 인셉션 모델은 그것들을 전부 다 실행해서 함께 엮는 것을 생각해냈습니다.
계산 비용 문제에 대해 1x1 합성곱을 사용해 병목 층을 만들어서 계산 비용을 상당히 줄일 수 있었습니다.
표현 크기를 줄이는 것이 성능에 지장을 줄지 걱정되긴 하는데, 이걸 적절하게 구현한다면 표현 크기를 줄이는 동시에 성능에 큰 지장 없이 많은 수의 계산을 줄일 수 있게 된 것입니다.
이것이 인셉션 모델의 기본 컨셉입니다.
'AI > Deep Learning' 카테고리의 다른 글
| C4W2L03-04 Resnets & Why ResNets Work (0) | 2022.11.06 |
|---|---|
| C4W2L07 Inception Network (0) | 2022.11.06 |
| C4W2L05 Network in Network (0) | 2022.11.06 |
| CSW3L06 Why Does Batch Norm Work? (0) | 2022.11.06 |
| Depth Estimation Related work (Stereo matching, Depth from single images, multi-view stereo, DPSNet) (0) | 2022.08.26 |
- Total
- Today
- Yesterday
- 도커
- 도커 컨테이너
- cs231n
- 파이썬 클래스 다형성
- vscode 자동 저장
- Prompt
- 프롬프트
- few-shot learning
- 구글드라이브서버다운
- 서버에다운
- 데이터셋다운로드
- clip
- support set
- NLP
- 구글드라이브서버연동
- stylegan
- prompt learning
- 파이썬 클래스 계층 구조
- 퓨샷러닝
- 파이썬 딕셔너리
- 구글드라이브다운
- python
- 딥러닝
- docker
- 서버구글드라이브연동
- 파이썬
- CNN
- Unsupervised learning
- 구글드라이브연동
- style transfer
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |